
カイ2乗分布表|データ解析の秘密【東京情報大学・嵜山陽二郎博士のAIデータサイエンス講座】

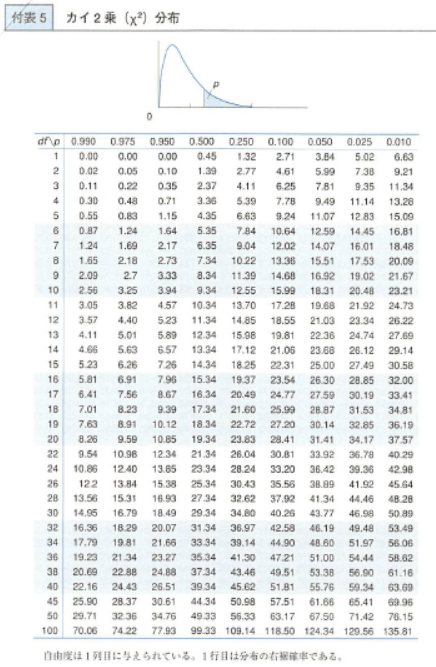
カイ二乗分布表は、正規分布に従う複数の確率変数の二乗和が従う分布を利用し、カテゴリカルデータの分析や分散の検定で用いられる確率分布表です。自由度は標本数やパラメータ数に基づき決定され、表では特定の自由度とカイ二乗値に対応する確率が示されています。自由度が大きいほど分布は正規分布に近づきます。カイ二乗検定では、データセットのカイ二乗値を計算し、表から対応する自由度の行とそのカイ二乗値の列を参照することで、その値が偶然によるものか統計的に有意かを判定します。このようにカイ二乗分布表は、統計的検定や解析における重要なツールとして広く活用されています。
![]() ▼▼▼▼▼▼▼▼
▼▼▼▼▼▼▼▼
チャンネル登録はこちら
カイ二乗(χ2)分布表は、統計学や確率論において使用される確率分布の一種です。
カイ二乗分布は、正規分布に従う複数の確率変数の二乗和が従う分布であり、主にカテゴリカルデータの分析や分散の検定などで使われます。
カイ二乗分布表は、特定の自由度(自由度は標本数から推定されるパラメータの数)に対するカイ二乗値に対する確率を示した表です。
一般的に、自由度が大きくなるにつれてカイ二乗分布は正規分布に近づきます。
カイ二乗分布表の使用法は以下の通りです:
自由度を決定します。通常、自由度はカイ二乗検定や分析の対象となるデータの数やパラメータの数によって決まります。
あるカイ二乗値が与えられた場合、対応する自由度の行とそのカイ二乗値の列を見つけます。
表の中のそのセルに示された値が、そのカイ二乗値に対する確率です。これは、そのカイ二乗値がその自由度の下で発生する確率を示しています。
例えば、カイ二乗検定を行う際に、あるデータセットのカイ二乗値が計算された場合、その値がカイ二乗分布表における対応する自由度の行と列でどのような確率に相当するかを見ることができます。
これにより、その値が偶然によるものか、または統計的に有意なものかを判断することができます。
カイ二乗分布表は統計的検定や解析の基礎的なツールの一つであり、統計学の分野において広く使用されています。

カイ二乗(χ2)分布表は、統計学や確率論において広く使用される確率分布の一つであり、特にカテゴリカルデータの分析や分散の検定などでその威力を発揮します。カイ二乗分布は、正規分布に従う複数の確率変数の二乗和が従う分布であり、この特性を活用して、データの分布や適合性を評価したり、独立性を検定したりします。例えば、あるデータが期待される分布にどの程度一致しているかを調べる適合度検定や、異なるカテゴリ間で観測された頻度が独立であるかどうかを判断する独立性の検定など、実用的な場面で頻繁に用いられます。このようなカイ二乗検定を行う際に必須となるのがカイ二乗分布表です。カイ二乗分布表は、特定の自由度(degrees of freedom: df)に対して、カイ二乗値とその値に対応する確率を示した表であり、これにより計算されたカイ二乗値が統計的にどのような意味を持つかを判断する助けとなります。自由度はデータの数や分析に使用されるパラメータの数に依存しており、一般的に自由度が大きくなるとカイ二乗分布は正規分布に近似します。これにより、データ量が多い場合でも適切な統計解析が可能になります。
カイ二乗分布表の具体的な使用方法を説明すると、まず自由度を決定する必要があります。自由度は一般に、「観測データの数?推定されたパラメータの数」で計算され、これにより解析の対象となるデータやモデルに応じて適切な行を選択できます。次に、計算されたカイ二乗値を用いて、表の中で該当する自由度の行とそのカイ二乗値の列を探します。この表の中のセルに示されている値が、そのカイ二乗値に対応する確率を意味します。この確率は、統計的な意味で「そのカイ二乗値が偶然発生する確率」を示し、これを用いて統計的有意性を判断します。一般に、有意水準(例えば0.05や0.01など)を基準にして、この確率が有意水準以下であれば、観測されたカイ二乗値は統計的に有意であると解釈されます。これにより、例えばある観測結果が偶然によるものなのか、それとも統計的に有意な違いがあるのかを明確にすることができます。
カイ二乗分布表を用いた具体的な応用例を挙げると、例えば適合度検定では、データセットが理論的な分布(例えば正規分布やポアソン分布)に適合しているかどうかを評価します。この検定では、観測された頻度と期待される頻度の間の差異が計算され、その差異をカイ二乗分布を用いて統計的に評価します。差異が小さい場合、データは期待される分布に十分適合していると判断されます。一方、独立性の検定では、二つのカテゴリカル変数が独立であるかどうかを判断します。例えば、ある薬剤の効果が性別によって異なるかどうかを検証する場合、性別と薬剤の効果をクロス表にまとめ、それぞれのセルの観測頻度と期待頻度を比較します。ここでも、カイ二乗分布を用いて観測された差異の有意性を検定します。
さらに、分散分析や多変量解析においてもカイ二乗分布は重要な役割を果たします。例えば、分散の均一性を検定する Bartlett 検定や Levene 検定では、カイ二乗分布が用いられます。また、モデル適合性の評価や、フィッシャーの正確検定などにも関連しています。これらの解析では、適切な自由度の選択が重要であり、それに応じたカイ二乗分布表の利用が求められます。
カイ二乗分布表の構造や特徴をさらに詳しく見ていくと、カイ二乗分布は右に裾が長い非対称な形状を持つことが特徴です。しかし、自由度が増えるにつれてこの分布は次第に対称性を帯び、正規分布に近づきます。これは、中心極限定理に基づく特性であり、大量のデータがある場合にはカイ二乗分布を正規分布で近似して解析を行うことも可能です。このようにカイ二乗分布表は、データが少ない場合でも、大規模データの場合でも柔軟に対応できるツールとなっています。
また、カイ二乗分布表の歴史的背景に触れると、統計学者カール・ピアソン(Karl Pearson)によって19世紀末に初めて提唱されました。彼はカテゴリカルデータの解析における分布の重要性を認識し、現在でも用いられるカイ二乗検定の基礎を築きました。この発展により、カイ二乗分布表は科学、医療、社会学など、あらゆる分野で標準的なツールとして利用されています。
結論として、カイ二乗分布表は統計的検定における基礎的なツールであり、観測されたデータの適合性や独立性を評価するために広く使用されます。自由度の決定、カイ二乗値の計算、表の利用を通じて、データの解釈や意思決定を支援する重要な役割を果たします。その応用範囲は幅広く、統計学の基本から応用分野に至るまで多岐にわたります。







