
�T���v���T�C�Y�ʼn𖾁I�L�Ӎ��̔閧�y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z

�L�Ӎ��̌��o�ɂ͓K�ȃT���v���T�C�Y���K�v�ł���A���̐v�ɂ̓������i����̉ߌ�̊m���j�A�������i����̉ߌ�̊m���j�A�����ăG�t�F�N�g�T�C�Y���d�v�Ȗ������ʂ����܂��B�������͒ʏ�0.05�Ɛݒ肳��A����͋A���������^�ł���ɂ�������炸�A����đΗ��������̑����Ă��܂����X�N��\���܂��B�������́A�Η��������^�ł���ɂ��ւ�炸�A����ċA���������̗p���Ă��܂����X�N�ŁA�ʏ�0.2�Ɛݒ肳��܂��B����ɑΉ����錟�o�͂�1-���ŁA��������ꍇ�ɂ���𐳂������o����\�͂��Ӗ����A0.8�ɐݒ肳��邱�Ƃ������ł��B�G�t�F�N�g�T�C�Y�́A��Q�Ԃ̌��ʂ̑傫����ʓI�ɕ\�������̂ŁA�傫���قnj��ʂ������ł���Ɖ��߂���܂��B�����̒l����ɃT���v���T�C�Y���v�Z����A�K�ȃT���v���T�C�Y�Ɋ�Â��������v�́A��������_�����X�N���ŏ������A�����̐M���������߂܂��B
![]() ����������������
����������������
�`�����l���o�^�͂�����
�ڎ� �T���v���T�C�Y�ʼn𖾁I�L�Ӎ��̔閧�y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z
�������邱�Ƃ������̂ɂ̓T���v���T�C�Y�i�m�j���K�v
�����v��@�̂Ȃ��ŁA�W�{�̑傫���i�T���v���T�C�Y�j��ݒ肷�邱�Ƃ͂ƂĂ���ł��B
�Ⴆ�A�����i���b�g�j�ɂ���K���}�O���u�������܂𓊗^�����Ƃ��ɁA�����w���O���r���ʂ��ω����邩�ǂ����A���������邽�߂Ɏ������s���A�ȉ��̌��ʂ�����ꂽ�Ƃ��܂��i�P�ʁFmg/mL�j�B
�ΏƌQ158151151150148157
����Q143133147144151158
���āA�����Q�Q�ɂ��āi�Ɨ��Q�Q�A�s�����U�����肵���jt-���������{�����Ƃ���A
p=0.1298
�Ƃ����l�������A�L�Ӎ����Ȃ��̂ŁA�K���}�O���u�������܂̓��^�̓w���O���r���ʂɉe�����y�ڂ��Ȃ��ƍl������A�ƌ��_���܂����B
���̌��_�͐������ł��傤���B
�m����t-�����̕��@���̂͐��������A���茋�ʂ��L�Ӎ��Ȃ��A�Ƃ����̂��������ł��B
���͂��̎��ł��B
�u���܂̓��^�̓w���O���r���ʂɉe�����y�ڂ��Ȃ��v
�ʂ����Ă����܂Ō����Ă��ǂ��ł��傤���B
�����ŋA�������ƑΗ����������܂��B
�A�������F���ܓ��^�Q�ƑΏƌQ�̊ԂŃw���O���r���ʂɍ����Ȃ�
�Η������F���ܓ��^�Q�ƑΏƌQ�̊ԂŃw���O���r���ʂɍ�������
��������̍l�����K����ƁA�����Ȃ��Ƃ����A��������ے肵�āA�Η�����������܂��B
�Η��������{���ɐ�������A�A�����������p���Η��������̑�����̂͐��������f�ɂȂ�܂��B
�������Ȃ���A�Η��������������ɂ��ւ�炸�A���̗�̂悤�ɁA�A�����������p�ł��Ȃ��̂őΗ��������̑��ł��Ȃ��ꍇ������܂��B
�����͏d�v�ł����A�����܂Łu�Η��������̑��ł��Ȃ��v�Ƃ��������̂��Ƃł����āA�u�Η�������ے�v���邱�Ƃ͂ł��Ȃ��̂ł��B
�܂�A�L�Ӎ������Ȃ���������Ƃ����č����Ȃ��Ƃ܂Ō����̂͌��������Ƃ������ƂɂȂ�܂��B
���ۂ��̃O���u�������܂́A�����w���O���r���ʂ������邱�ƂŗL���Ȑ��܂ŁA������͎̂����i�������j�̂��ƂƂȂ��Ă��܂��B
�����炭�A�T���v���T�C�Y���s�����Ă���̂ŗL�Ӎ������Ȃ��������̂ł͂Ȃ����ƍl�����܂��B
���āA�ł͂ǂ̂悤�ɂ��ēK�ȃT���v���T�C�Y�����߂���悢�̂ł��傤���B

�T���v���T�C�Y�̐v�F�������E�������E�G�t�F�N�g�T�C�Y
�悸�́A��������f�����Ă��܂��m���i�������E�������j���͂��߂���ݒ肷�邱�Ƃł��B
�菇�͈ȉ��̒ʂ�B
�@�A���������������̂ɑΗ��������̑�����i��������Ƃ��Ă��܂��j�m���i��P��̉ߌ�̊m���F�������j��ݒ肷��B�ʏ�̓����O�D�O�T
�A��������i�Η��������������j�ɂ�������炸�����Ȃ��Ƃ݂Ȃ��Ă��܂��m���i��Q��̉ߌ�̊m���F�������j��ݒ肷��B�ʏ�̓����O�D�Q�B�t�ɂP�|���͍�������̂𐳂�����������ƌ��o����m���ŁA���o�͂Ƃ����܂��B�ʏ�O�D�W�ɐݒ肵�܂��B
�B���{�����\�������̃G�t�F�N�g�T�C�Y�iEffect Size�FES�j���v�Z����BES�͌��ʗʂƂ������A�Q�Q�̍����Q�Q�̋��ʂ̕W�����Ŋ������l�ł��BES���傫���قnj��ʂ��傫���Ƃ����Ӗ��ł��B
�C�����̒l�����ƂɁA�T���v���T�C�Y���v�Z���܂��B
�v�Z���Ŏ����ƈȉ��ł��B
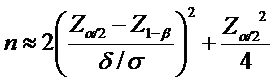
�ڍׂ͊������܂����A�v�������O�D�O�T�A�����O�D�Q�A�d�r���^�Ђ����܂�A�������܂��Ƃ������Ƃł��B
��̓��������̗�ɖ߂�܂����A
���ǁA���̎��������̂��߂̍ŏI�����ł͂Ȃ��A�T���v���T�C�Y����̂��߂̗\�������Ƃ݂Ȃ��A�Ƃ����̂��������킯�ł��B
�ȉ��v�Z��ł����A�����O�D�O�T�A�����O�D�Q�A�G�t�F�N�g�T�C�Y���\�������̌��ʂO�D�X�W�V�ƌv�Z����܂����̂ŁA�K�v�ȃT���v���T�C�Y�͈�Q������P�W�ƌ��ς��邱�Ƃ��ł��܂����B
���ʂȃ\�t�g���g��Ȃ��Ă��A�}�C�N���\�t�g�G�N�Z���ŊȒP�Ɍv�Z���邱�Ƃ��ł��܂��B
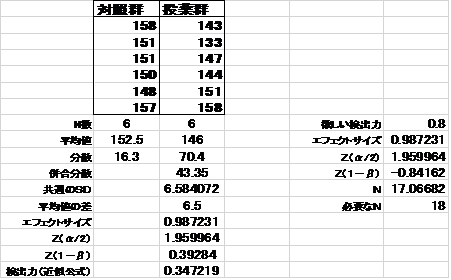
���v�\�t�g���Ȃ��Ă��A�������Excel�e���v���[�g�ŃT���v���T�C�Y���ȒP�Ɍv�Z�ł��܂��B
�������Excel�e���v���[�g���~�������͈ȉ����₢���킹�t�H�[�����烊�N�G�X�g������͍����グ�܂��B
�T���v���T�C�Y�̐v�͎����v���d�v�ł��B
�������i����̉ߌ�̊m���j�A�������i����̉ߌ�̊m���j��ݒ肵�A�G�t�F�N�g�T�C�Y��\����������v�Z���邱�ƂŁA�œK�T���v���T�C�Y�𐄒肷�邱�Ƃ��ł��܂��B
ChatGPT�ɕ����Ă݂�
�v�����v�g
���Ȃ��͍ō��̃f�[�^�T�C�G���e�B�X�g�ł��B
�T���v���T�C�Y�̌��ߕ��ɂ��ĉ�����Ă��������B
#��������F
�T���ł��킩�镽�Ղȓ��{���
��������300�����x
ChatGPT�̉�
�T���v���T�C�Y�����߂�̂́A�����⒲��������Ƃ��ɒ��厖�ȃX�e�b�v�ł��B�T���v���T�C�Y���Ă����̂́A���ׂ����W�c����I�ԁA����������Ɏg���l����̂̐��̂��ƁB���̐������߂�ɂ́A�������厖�ȃ|�C���g�������B�悸�͖��m�ȖړI�F���ׂ������������茈�߂悤�B�����Ńo���G�[�V�����F�W�c���ǂꂭ�炢�o���o�������d�v�B�o���o�������傫���ƁA�����Ƒ����̃T���v�����K�v�B�����Ő��x�F���ʂ̐��m������B�����Ɛ��m�����~�����Ȃ�A�T���v���T�C�Y��傫�����悤�B�v�Z���F���v�w�̌v�Z�����g���āA�����̗v�f���l�����ăT���v���T�C�Y���o�����Ƃ��ł���B�ȒP�Ɍ����ƁA����m�肽�����ɂ���āA�K�v�ȃT���v���̐����ς���Ă���B�����āA���̐������߂邱�ƂŁA�M���ł��錋�ʂ���ɓ���邱�Ƃ��ł����B
�֘A�����N

![]() �y�g�b�v�y�[�W�֖߂�z
�y�g�b�v�y�[�W�֖߂�z![]() �yYouTubeChannel�z
�yYouTubeChannel�z![]() �y���v��͍u�`��b�z
�y���v��͍u�`��b�z![]() �y���v��͍u�`���p�z
�y���v��͍u�`���p�z![]() �yChatGPT�EPython�EExcel�z
�yChatGPT�EPython�EExcel�z![]() �y���ϗʉ�́z
�y���ϗʉ�́z![]() �y��Ó��v��́z
�y��Ó��v��́z







