
ホットデック法で正確に欠測値補完!【東京情報大学・嵜山陽二郎博士のAIデータサイエンス講座】

ホットデック法は、データの欠測値を同じデータセット内から類似した個体を見つけ、その値で補完する手法です。一方、コールドデック法では、異なるデータセットから類似個体を探して欠測値を補完します。これらの方法では、類似性の定義が重要となり、数値データでは距離尺度(例: ユークリッド距離)、カテゴリカルデータではコサイン類似度などが使われます。完全に一致する個体がない場合は、部分的な類似性を利用することが求められます。また、機械学習やクラスタリングなどを使い、最も適した個体を見つけ出すことが可能です。欠測値の補完には平均値、回帰分析、または複数の類似個体の情報を組み合わせる方法も用いられます。これにより、柔軟に類似性を拡張し、より正確なデータ補完が可能になります。
![]() ▼▼▼▼▼▼▼▼
▼▼▼▼▼▼▼▼
チャンネル登録はこちら
ホットデック法(hot deck method)
欠測への対処法のうちの代入法の一つがホットデック法(hot deck method)です。
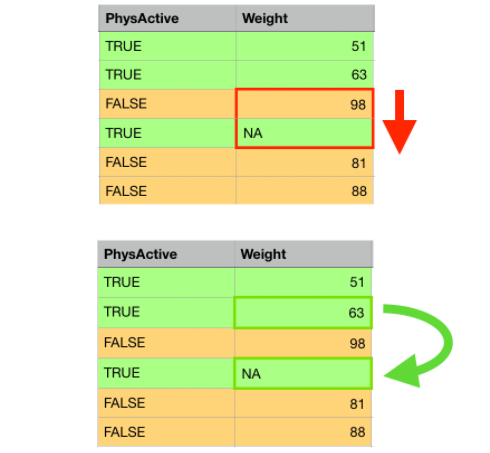
欠測を含むデータがあったとき、その個体と何らかの意味で類似の個体を同じデータセットの中から探し出し、その類似個体の当該変量の値を欠測箇所の値とする方法です。

類似個体を異なるデータセットから探し出す方法はコールドデック法(cold deck method)といいます。
ここで当然問題となるのは「類似」の意味とデータセットからの具体的な検索法です。
データの測定項目が多いときは、観測箇所かが全く同じ個体は存在しないであろうから何らかの意味であいまいな類似性を採用しなくてはなりません。
コールドデック法(cold deck method)
コールドデック法は、データ解析において欠損値を補完する際に使用される手法の一つです。
この手法では、欠損値を持つ個体やデータポイントに対して、同じデータセット内から類似した個体を見つけ出し、その類似個体の情報を利用して欠損値を補完します。
この手法は、データの欠損が比較的少ない場合や、欠損値を補完するための十分な情報が利用可能な場合に有効です。
まず、欠損値を補完するためには、類似性の定義が必要です。
類似性は、データセット内の個体やデータポイント間の関係を示す尺度であり、通常は特徴量や属性の類似性に基づいて定義されます。
具体的には、数値データの場合は距離尺度(例: ユークリッド距離)や相関係数、カテゴリカルデータの場合は類似度尺度(例: コサイン類似度)が使用されます。
類似性の定義は問題やデータの性質によって異なるため、適切な尺度を選択することが重要です。
次に、類似個体の探索が行われます。これには、類似性の定義に基づいて、欠損値を持つ個体と類似した特性を持つ個体を見つける方法が使用されます。
ただし、完全に同じ個体が存在しない場合や、データが欠損している場合には、部分的な類似性や類推が必要になります。
類似個体の探索には、機械学習アルゴリズムやクラスタリング手法などが使用されることがあります。
最後に、欠損値の補完が行われます。類似個体が見つかった場合、その個体の対応する属性の値を欠損値の補完に使用します。
類似性が高い個体であれば、補完された値も信頼性が高くなりますが、類似性が低い場合は補完された値の信頼性が低くなります。
欠損値の補完には、平均値、中央値、最頻値などの統計的手法や、回帰分析やクラス分類などの機械学習手法が使用されることがあります。
また、複数の類似個体から得られた情報を組み合わせて補完する方法もあります。
データの測定項目が多い場合、完全に同じ個体が存在しない可能性が高いため、柔軟な類似性の定義が必要です。
たとえば、属性の一部が類似している個体や、同じ属性が似ている複数の個体の平均値を使用するなど、類似性の定義を拡張することが考えられます。
これにより、より適切な類似個体を見つけて欠損値を補完することが可能になります。
総括すると、コールドデック法は欠損値を補完するための有用な手法であり、適切な類似性の定義と適切な補完手法を使用することで、データの品質を向上させることができます。
関連記事








