
�W���덷�ʼn𖾁I���萸�x�̔閧�y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z

�W���덷�Ƃ́A�W�{���ς̕��z�̕W�����ł���A�ꕽ�ς̐��萸�x�������w�W�ł��B��W�c���瑽���̕W�{�𒊏o����ƁA�W�{���ς͐��K���z�ɏ]���܂��B�W���덷�͕W�{�T�C�Y���傫���Ȃ�قǏ������Ȃ�A���萸�x�͌��サ�܂��B�W�����Ƃ͈قȂ�A�f�[�^�̐��𑝂₷���Ƃŏ������Ȃ�͕̂W���덷�̕��ł��B���S�Ɍ��藝�ɂ��A�W�{���ς̕��z�͐��K���z�ɏ]���A���̕W�������W���덷�ɂȂ�܂��B�W���덷�̑傫���́A�W�{���o�̕��@��W�{�̃T�C�Y�Ɉˑ����A�}�W���덷�͈̔͂ɕꕽ�ς��܂܂��m���͖�68%�ł��B��荂�����萸�x�����߂�ꍇ�́A95%�M����Ԃ�p���邱�Ƃ���ʓI�ł��B���̋�Ԃ͕W���덷�̖�1.96�{�ɑ������A���萸�x��95%�ɍ��߂邱�Ƃ��ł��܂��B�W���덷�́A���v�I�������s����ŏd�v�ȊT�O�ł���A�f�[�^���͂ɂ����鐸�x�̗����ɕs���ł��B
![]() ����������������
����������������
�`�����l���o�^�͂�����
���v����̍u�`�ōł��悭���鎿��̈���A�W�����ƕW���덷�̈Ⴂ�͉����A�Ƃ�������ł��B
�W�������W���덷�͈ꎚ�Ⴂ�ł����A���̈Ӗ�����Ƃ���͑啪�Ⴂ�܂��B
���܂ɁA�u�f�[�^�̐��𑝂₷�Ƃ�����������Ȃ�A�W�������������Ȃ�v�Ƃ����̂����ɂ��邱�Ƃ�����܂����A����͊ԈႢ�ł��B
�W�����Ƃ͂���̎w�W�ł��B
����͂����܂ł�����ł���A�f�[�^�̐��𑝂₵���Ƃ���ŏ������Ȃ���̂ł͂���܂���B
�f�[�^�̐��𑝂₷�Ə������Ȃ�͕̂W���덷�̕��ł��B
�ł́A�W���덷�Ƃ͉����ɂ��čl���Ă݂܂��傤�B
�ڎ� �W���덷�ʼn𖾁I���萸�x�̔閧�y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z
��W�c����W�{����������Ƃ�
�W���덷�𗝉����邽�߂ɂ́A�������v�̊�{�A���Ȃ킿��W�c����W�{���Ƃ��A�Ƃ����l������悸�������邱�Ƃ��K�v�s���ł��B
�Ⴆ�Γ��{�l�S�́A1��3�疜�l�̕��ϑ̉���m�肽���Ƃ��܂��B
����́A�c�O�Ȃ��玄�����͒m�邱�Ƃ͂ł��܂���B
1��3�疜�l�̑̉��𑪒肵�f�[�^���W�߂邱�Ƃ͕s�\������ł��B
�^�̒l�͐_�l�������m���Ă��܂��B
���̐^�̒l���A
�ꕽ�ρ@36.5�x
��W�����@�@2.0�x
�Ƃ��܂��傤�B
�����ŁA���{�l�S�̂��烉���_����100�l�̕W�{�𒊏o�����Ƃ��܂��B
�����_���ɁA�Ƃ����Ƃ��낪�d�v�ł��B�j���ɕ�����A����҂ɕ����肵�Ă͂����܂���B
���̕W�{�̕��ϒl�𑪒肵���Ƃ���A�W�{���ς�36.6�x�������Ƃ��܂��B
�����W�{�͕�W�c�̏k�}�ł��B
�܂�A��W�c������ł��Ȃ����߂ɁA���W�c�ł���W�{�𑪒肷�邱�ƂŁA�ꕽ�ς��W�����𐄑����܂��B
���ꂪ�������v�̊�{�I�l�����ł��B
���������āA�W�{����36.6�x�́A�ꕽ��36.5�x�ƑS�������łȂ��Ƃ��A�߂��l�ł���K�v������܂��B
�Ƃ����܂����A�W�{���o�ɕ肪�Ȃ��Ȃ�A�߂��l�ɕK���Ȃ�܂��B
���āA����100�l�̕W�{���o����������̉s���Ă݂܂��B
���ۂɂ͂��̂悤�ɂ�������̉s�����Ƃ͂Ȃ��̂ł����A�����͑z���͂����Ă݂܂��傤�B
����ƁA�ȉ��̌��ʂ������܂��B
100�l�i�W�{A�j�@36.6�x
100�l�i�W�{B�j�@36.4�x
100�l�i�W�{C�j�@36.5�x
100�l�i�W�{D�j�@36.3�x
100�l�i�W�{E�j�@36.7�x
�E
�E
�E
���̂悤�ɁA�ǂ��36.5�x�ɋ߂��l�ɂ͂Ȃ�̂ł����A�ǂ����Ă��ꕽ��36.5�x����͏�������܂��B
�܂��A�W�{�Ԃł��A�l����������܂��B
����͎d�����Ȃ����Ƃł��B�Ȃ��Ȃ�ǂ������ׂɕ�W�c���璊�o�����W�{�ł����A�S�������W�{�ł͂���܂���B
100�l�̔w�i�͂��ꂼ��قȂ�̂ŁA���ς������قȂ�͎̂d�����Ȃ��̂ł��B
�ł�����͏����ł��B�傫���قȂ邱�Ƃ͂���܂���B
���āA���̕W�{���ς̕��z���l���܂��B
�܂�A��ł���36.6�x�A36.4�x�A36.5�x�Ƃ������W�{���ς̒l�̕��z���l���܂��B
����ƁA����͂Ȃ�����K���z�ɂȂ�܂��B
�K�����K���z�ɂȂ�܂��B
��������S�Ɍ��藝�Ƃ����܂��i���v�w�̑�藝�ƌĂ�Ă��܂��j�B
����͏��Ȃ��̂ŁA�ׂ��Ƃ������肪�ˌ^�̕��z�ɂȂ�܂��B
���̕��z�̕��ς́A�ꕽ�ςɂ��Ȃ�߂��l�ɂȂ�܂��B
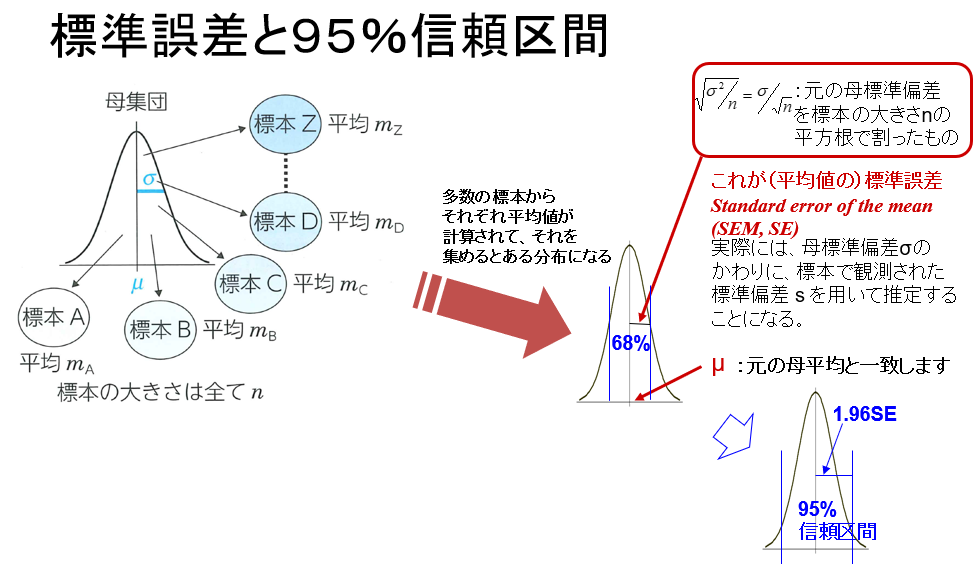
�����Ă��̕��z���W������������W���덷�ł��B
���̏ꍇ�́A��W������2�A�W�{�̑傫����100�l�ł�����A100�̕��������Ȃ킿10�Ŋ�����0.2���W���덷�ƂȂ�܂��B
�W�{���ς̕��z�́A��W�c�̕��z����1/10�ׂ��Ƃ��������z�ɂȂ�܂��B

�W���덷�͕ꕽ�ς̐��萸�x
���āA�����W���덷�̈Ӗ��ł����A�ꌾ�Ō����A�ꕽ�ς̐��萸�x������킵�܂��B
��������Ώ������قǁA�܂����W�{���ς̂肪�ˌ^���z���ׂ���ׂ��قǁA����̐��x�͍��܂�܂��B
�ł͐���̐��x�����߂�ɂ͂ǂ�������悢�ł��傤���B�W�{��傫������悢�̂ł��B
���W�{�̑傫����100�l�Ȃ̂ŁA100�̕������܂�10�ŕ�W�������������ׂ��肪�ˌ^�̕��z�ł����A����������ƍׂ����悤�Ǝv���A�Ⴆ��400�l�ɂ���B
����ƁA400�̕������܂�20�Ŋ��邱�ƂɂȂ�̂ŁA�����ƍׂ��Ȃ�܂���ˁB
10000�l�ł����100�Ŋ��邱�ƂɂȂ�܂��̂ł��Ȃ�ׂ��Ȃ�܂��B
10000�l�̕W�{���ς́A�ꕽ�ςɂقړ������Ƃ����Ă������ʂł��傤�B
�������̕��W�{���o����ςɂȂ�܂��̂ŁA�����̓o�����X���Ƃ�܂��B
�W���덷�̐��萸�x��68%
�W���덷�͕ꕽ�ς̐��萸�x�̎w�W�Ƃ����܂������A�ł́}�W���덷�͈̔͂ɕꕽ�ς��܂܂��m���͂ǂ̈ʂł��傤���B
���́A��68%�ŁA�債�����Ƃ͂Ȃ��̂ł��B
�܂�A�c���32%�͕ꕽ�ς̐�����͂����Ƃ������Ƃł��B
�W�{��100�Ƃ�A�e�W�{�ŕW�{���ς��v�Z����ƁA68�̕W�{���ς́}�W���덷�͈̔͂Ɋ܂܂�܂����A32�̕W�{���ς́}�W���덷�͈̔͂���͂ݏo���Ă��܂��Ƃ������Ƃł��B
����͂悭�悭�l����Ɠ�����O�Ȃ��ƂŁA�W���덷�͕W�{���ς̕��z�ɂ����Ă��W�����ɑ�������̂ŁA�}�W�������f�[�^���J�o�[����͈͂��Ȃ킿68%�ɑ������܂��B
������ɂ��Ă��A�W���덷��68%�̐��萸�x�Ƃ����̂͂��܂�ɂ��e���ł��B
�����ŁA95%�M������Ƃ����l�������K�v�ƂȂ�܂��B
�W���덷��1.96�{�������̂�95%�M������ł��B
�W���덷��68%�̐��萸�x�ɑ��A95%�M�������95%�̐��萸�x�ł��B
ChatGPT�ɕ����Ă݂�
�v�����v�g
���Ȃ��͍ō��̃f�[�^�T�C�G���e�B�X�g�ł��B
�W���덷�ɂ��ĉ�����Ă��������B
#��������F
�T���ł��킩�镽�Ղȓ��{���
��������300�����x
ChatGPT�̉�
�W���덷���Ă����̂́A�X�̃T�������̕��ϑ̏d�ׂ����Ƃ��ɁA�ǂꂭ�炢���m�ɑ���Ă��邩���������l�ł��B�T���̈�Q���琔�C��I��ő̏d�𑪂�ƁA���̕��ϒl�͖�����Ƃ��Ⴂ�܂���ˁB�W���덷�́A���̕��ϒl�̃Y���̑傫���������Ă�����ł��B�Ⴆ�A100�C�̃T������10�C��������̏d�𑪂��ĕ��ς��o���ƁA���̕��ϒl�͂��낢��ς��܂��B�����̕��ϒl�̂�����������قǁA�������̑��������ϑ̏d�́u�{���̕��ϑ̏d�v�ɋ߂��ƌ����܂��B�W���덷���������قǁA���M�����̍������ϒl���Ă���؋��ł��B�܂�A�W���덷�́A�T���v�����瓾��ꂽ���ϒl���A�ǂꂾ�����m���i�܂��͐M���ł��邩�j�������Ă����w�W�Ȃ�ł��B
�֘A�����N

![]() �y�g�b�v�y�[�W�֖߂�z
�y�g�b�v�y�[�W�֖߂�z![]() �yYouTubeChannel�z
�yYouTubeChannel�z![]() �y���v��͍u�`��b�z
�y���v��͍u�`��b�z![]() �y���v��͍u�`���p�z
�y���v��͍u�`���p�z![]() �yChatGPT�EPython�EExcel�z
�yChatGPT�EPython�EExcel�z![]() �y���ϗʉ�́z
�y���ϗʉ�́z![]() �y��Ó��v��́z
�y��Ó��v��́z







