
���q�Ɠ������𖾁I���U���͖@�̊�{�Ɖ��p�y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z

���U���͖@�́A�����̈��q�₻�̐����������l�̕��ςɗ^����e���ׂ铝�v��@�ł��B���̎�@�́A�f�[�^�̕ϓ���v�������ɕ����A����ʂ���ݍ�p�Ȃǂv�I�Ɍ��肵�܂��B���ʂ͕��U���͕\�ɂ܂Ƃ߂��A�����a�⎩�R�x�����Ƃɉ�͂���܂��B�����v��ł͈��q�Ƃ��̐�����ݒ肵�A�����_�����ɂ��f�[�^���W���s���܂��B���U���͂́A���ϓ������ԕϓ��i���q�ԕϓ��j�Ƌ����ϓ��i�덷�ϓ��j�ɕ����A���q�̌��ʂ��덷�ϓ��Ɣ�r���ėL�Ӑ������肵�܂��B�Ⴆ�A�������x�̐����ʎ����f�[�^�̂������͂���ꍇ�A���q�ɂ��e������肵�A����ʂ��������܂��B���̎�@�͌Â����痘�p����A���݂ł��f�[�^��͂̏d�v�ȃc�[���Ƃ��Ċ��p����Ă��܂��B
![]() ����������������
����������������
�`�����l���o�^�͂�����
�ڎ� ���q�Ɠ������𖾁I���U���͖@�̊�{�Ɖ��p�y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z
�����̌��ʂ𐳂������߂���ɂ́A���U���͖@�ɂ��Ȃ���Ȃ�܂���B
�������A���U���͖@�̊�b�ƂȂ闝�_�͏��S�҂ɂƂ��ē���ł��B
�����ŁA�ȉ��ŕ��U���͖@�̐��藧�����ł��邾�����Ղȕ\���ʼn�����܂����B
���U���͖@�Ƃ�
�P�������͕����̈��q�̈قȂ鐅���������l�̕��ςɂǂ̂悤�ȍ��������炷���v�I�ɒ��ׂ��@�ł��B
���U�̕��͂ł͂Ȃ��A���U��p�������ϒl�̕��͂ł��B
���q���P�̏ꍇ�ɂ͈ꌳ�z�u���U���́A�Q�̏ꍇ�ɂ͓z�u���U���͂Ƃ����A����ȊO�ɂ��������蕪�U���͂ȂǁA�f�[�^�̎����ɉ��������͖@������܂��B
���U���͎͂���ʁA���ݍ�p�Ȃǂ̌��ʂ���`���f���̌`�ɕ\���A�덷�̐��K���̉���̉��ōŏ��Q��@�ɂ��e���ʂ𐄒肵�A���̗L�Ӑ��v�I�Ɍ��肵�܂��B
���ʂ͕��U���͕\�̌`�ɂ܂Ƃ߂��܂��B��v�Z�̎���ɊJ�����ꂽ��@�ł����A���݂ł��ˑR�Ƃ��čŗL�͂̕��͎�@�ł��B
���U���͕\
���U���͂ɂ����镽���a����ю��R�x�̕����Ȃ�тɂ����̒l�Ɋ�Â�����̎菇�ƌ��ʂ�\�̌`�ɂ܂Ƃ߂����̂ł��B
��v�Z�̎���ɂ͌v�Z�̃`�F�b�N���ł���Ƃ������Ƃŕ��͂̏d�v�ȃc�[���ł������A�R���s���[�^�ł̌v�Z���嗬�̌��݂ł����͌��ʂ̉��߂ɂ͌������Ȃ��\�ƂȂ��Ă��܂��B
��A���͂Ȃǂł����͌��ʂ̗v��Ƃ��ĕ��U���͕\���p�����܂��B
�ϑ��l�����f���ւ̓��Ă͂܂蕔���Ǝc�������ɕ�����Ƃ������_�͓��v���͑S�Ăɋ��ʂ�����̂ł��B

�����v��@�ƕ��U����
�������s���ꍇ�A�ړI�Ƃ�������l�ɉe���̂���ϓ��v���̒�����A���̎����ɂƂ�グ�����������q�ifactor�j�Ƃ�т܂��B
���̈��q��ʓI�E���I�ɕς�������𐅏��ilevel�j�Ƃ����܂��B
�ʏ�A���q�̓��[�}���̑啶���ŕ\���i�Ⴆ��A, B, C�j�A�����͐����̓Y�����ɂ��\���܂��i�Ⴆ��A1, B1, C1�j�B
�����i�̍��������ŁA���������i%�j�ɑ��锽�����x�i���qA�j�̉e���ׂ邱�ƂɂȂ�܂����B�������x�Ƃ��ẮA
A1: 50�x�AA2: 55�x�AA3: 60�x�AA4: 65�x
�̂S�������Ƃ�A�e�������ƂɂT�̌J��Ԃ��������s�����Ƃɂ��܂����B
�S�����͂Q�O��ƂȂ�܂����A���̎��������������_���Ɏ��{�������ʁA�ȉ��\�̂悤�ȍ��������̃f�[�^�܂����B
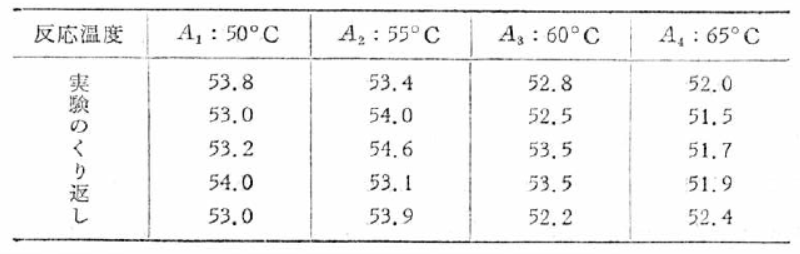
���̎����ł́A���q�ł��锽�����x���S�����Ƃ��Ă��܂��B
���܁A�\�̃f�[�^�����x�̐����ʂɐ}������ƁA�ȉ��}�̂悤�ɂȂ�܂��B
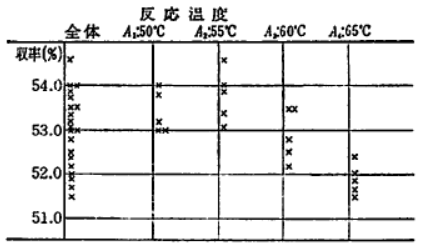
���̐}���疾�炩�Ȃ悤�ɁA�������x�������Ǝ����̃f�[�^�͕ω����܂��B
�������A�����������x�ł����������ɂȂ�̂ł͂���܂���B
�Ⴆ�AA1:50�x�̏ꍇ�ł́A�Œ�53.0%����ō�54.0%�܂ł���Ă��܂��B
�܂�A���̃o���c�L�̒��ɂ́A
�@�������x�̐�����ς������߂̃o���c�L
�A�����������x�̂��ƂŎ���������Ԃ����Ƃ��̃o���c�L
�Ƃ��A�����荇���Ă��邱�Ƃ��킩��܂��B
���܁A���̎����S�̂̃f�[�^�̂����Ă���o���c�L�����ϓ��Ƃ�сA�������x��ς������߂Ƀf�[�^�ɗ^������o���c�L�̕��������ԕϓ��i�܂��͈��q�ԕϓ��j�A�����������x�̒��Ŏ������J��Ԃ����Ƃɂ���ăf�[�^�ɗ^������o���c�L�̕����������ϓ��i�܂��͌덷�ϓ��j�ƌĂԂ��ƂƂ��A������}�̂悤�ɕ\�����Ƃ��ł��܂��B
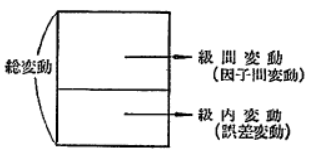
�����ŁA�����������x�̐�����ς������Ƃɂ���ăf�[�^�̃o���c�L���傫���Ȃ����Ƃ���A�e�ϓ��̊����͐}�̂悤�ɋ��ԕϓ����傫���Ȃ�ł��낤���A�������x�������Ă����܂�f�[�^�ɉe�����Ȃ��̂Ȃ�A�ȉ��}�̂悤�ɋ����ϓ��̊������傫���Ȃ�ł��傤�B
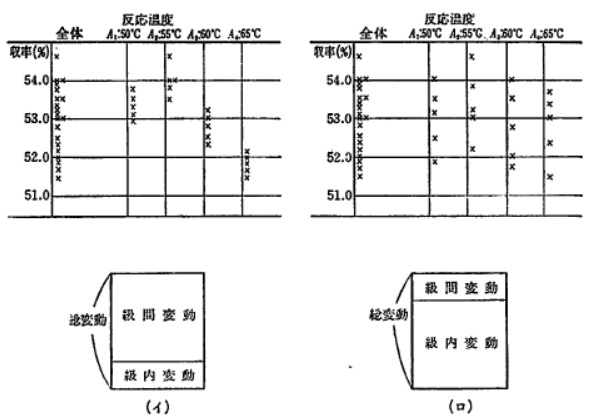
�����ŁA���q�̐�����ς������Ƃɂ����ʂ�����Ƃ������Ƃ́A�e�����̒��ł̃f�[�^�̃o���c�L�A���Ȃ킿�덷�ɑ��āA������ς������߉e�����F�߂���Ƃ������Ƃł��B
���������āA���q�̌��ʂ́A�������q�̐����̒��ł̃o���c�L�i�����ł͋����ϓ��j�Ɣ�r���Č��߂邱�Ƃ��K�v�ɂȂ�̂ł��B
�����ŁA���܁A�K���ȓ��v�ʂ�p���Ď����f�[�^�̃o���c�L��}�̂悤�ɕ������邱�Ƃ��ł���Ȃ�A���ϓ��̑傫�����r���邱�Ƃɂ���āA�������x��ς������Ƃɂ��e���A��ʂɂ͈��q�̌��ʁA���������ʁimain effect�j�Ƃ����܂����A����ׂ邱�Ƃ��ł��܂��B
���̂悤�ɁA�f�[�^�̂����Ă���ϓ����A���q��덷�Ȃǂ̗v�������ɕ����Ĉ��q�̌��ʂ����肷����@���A���U���͖@�Ƃ����܂��B
���U���͖@�́A�����̈��q�₻�̐����������l�̕��ςɗ^����e���v�I�ɒ��ׂ��@�ł���A�������ʂ̐��m�ȉ��߂��s����Ō������Ȃ��Z�p�ł��B���̎�@�́A�f�[�^�̕ϓ���v�������ɕ����A���ꂼ��̌��ʂv�I�Ɍ��肷�邱�Ƃň��q���^����e���̗L���f���܂��B���ɁA����ʂ���ݍ�p�Ȃǂ̌��ʂ��ǂ̒��x�����l�ɉe�����y�ڂ��Ă��邩����������ۂɗL�p�ł���A���`���f����ŏ����@��p���ėL�Ӑ�����͂��܂��B���ʂ͕��U���͕\�̌`�ɂ܂Ƃ߂��A�����a�⎩�R�x�Ƃ��������v�I�w�W�Ɋ�Â��Č��ʂ̗L�Ӑ������f����܂��B���̎�@�́A��v�Z���嗬����������ɊJ������܂������A���݂ł����̊�b�I�ȍl�����͕ς�炸�A�R���s���[�^�ɂ��v�Z�����y��������ɂ����Ă����ɏd�v�ȃf�[�^��͂̎�@�Ƃ���Ă��܂��B�Ⴆ�A�����i�̍��������ɂ����Ĕ������x�����������ɗ^����e���ׂ�ꍇ�A�������x�����q�Ƃ��Ď��グ�A���̐�����50�x�A55�x�A60�x�A65�x��4�i�K�ɐݒ肵�܂��B�e�������Ƃ�5��̌J��Ԃ��������s���A���v20��̎������ʂ��Ƃ��܂��B���̂悤�Ɏ��W���ꂽ�f�[�^�U���͂ɂ����邱�ƂŁA�������x�̐�����ω����������Ƃɂ�鍇�������̕ϓ��A���Ȃ킿���q�̌��ʂ�]�����邱�Ƃ��ł��܂��B��̓I�ɂ́A����ꂽ�f�[�^�����ԕϓ��i���q�ԕϓ��j�Ƌ����ϓ��i�덷�ϓ��j�ɕ������A�������x�̐�����ς������Ƃɂ��ϓ����f�[�^�S�̂̕ϓ��̒��łǂꂾ���傫�Ȋ������߂邩�͂��܂��B���̂Ƃ��A�������x��ω����������ʂ����v�I�ɗL�ӂł��邩�f����ɂ́A���q�̌��ʂ��덷�ϓ��Ɣ�r����K�v������܂��B�K�ȓ��v�ʂ��v�Z���A���҂��r���邱�Ƃň��q�̎���ʂ����肵�܂��B���̂悤�ɂ��ē����錋�ʂ���A�������x�����������ɉe����^����v���ł��邩�ǂ����m�ɂ��邱�Ƃ��ł��܂��B���U���͖@�́A�ꌳ�z�u���U���͂�z�u���U���́A�������蕪�U���͂ȂǁA���q�̐���f�[�^�̎����ɉ����ėl�X�Ȏ�@�����݂��܂��B�ꌳ�z�u���U���͂́A�P��̈��q��ΏۂƂ��A�قȂ鐅���������l�ɂǂ̂悤�ȍ��������炷���ׂ���@�ł��B����A�z�u���U���͂�2�̈��q�̌��ʂƂ��̌��ݍ�p���Ɍ������邱�Ƃ��ł��A��蕡�G�Ȏ����v�ɂ��Ή��\�ł��B�������蕪�U���͂́A�����팱�҂ɑ��ĕ����̏������J��Ԃ����肷��ۂɎg�p����A�f�[�^�̂���Ɍ̍����e����^����ꍇ�ɓK���Ă��܂��B�����̕��U���͖@�ł́A�ϑ��l�����f���ւ̓K�������Ǝc�������ɕ�����l��������{�ƂȂ�܂��B�Ⴆ�A�����S�̂̃f�[�^��������ϓ��ƌĂсA��������q�̌��ʂɂ��ϓ��i���ԕϓ��j�ƌ덷�ɂ��ϓ��i�����ϓ��j�ɕ������܂��B�������q�̐�����ω����������Ƃɂ��e�����傫����A���ԕϓ��̊��������債�A�t�ɉe����������������ϓ��̊������傫���Ȃ�܂��B���̂悤�Ƀf�[�^�̕ϓ������邱�ƂŁA���q�������l�ɗ^����e���̗L���v�I�Ɍ������邱�Ƃ��\�ƂȂ�܂��B�܂��A���U���͂͒P�Ȃ铝�v�I��@�Ƃ��Ă����łȂ��A�����v��@�̈�Ƃ��Ă����ɏd�v�Ȗ������ʂ����܂��B�����v��@�ł́A�ړI�Ƃ�������l�ɉe����^����v�������q�Ƃ��Ē�`���A���̈��q��ʓI�܂��͎��I�ɕω�����������𐅏��ƌĂт܂��B���q�͒ʏ탍�[�}���̑啶���ŕ\����i��FA, B, C�j�A�����͐����̓Y������p���Ď�����܂��i��FA1, B1, C1�j�B�����v��𗧂Ă�ۂɂ́A���q�Ɛ����̐ݒ肾���łȂ��A�����̏����������_�������邱�ƂŃf�[�^���W�ɂ��������ŏ����ɗ}���邱�Ƃ��d�v�ł��B�����_�������ꂽ�����̌��ʂ��瓾����f�[�^�́A���U���͂�ʂ��ĉ�͂���A���q�̌��ʂ���ݍ�p�̗L���m�ɂ��܂��B�Ⴆ�A�������x�����q�Ƃ��Đݒ肵���ꍇ�A�قȂ鉷�x�����������ɗ^����e�����r���邱�ƂōœK�ȏ�������肷�邱�Ƃ��ł��܂��B���̂悤�ɁA���U���͖@�́A�����f�[�^�̉��߂��Ȋw�I�ɗ��t���邾���łȂ��A�����v����������I�����ʓI�ɐi�߂邽�߂̊�Ղ���܂��B����ɁA���U���͕\�́A��͌��ʂ��킩��₷���������邽�߂̃c�[���Ƃ��Ă��d�v�ł��B���U���͕\�ɂ́A�����a�A���R�x�A���ϕ����AF�l�Ap�l�Ȃǂ̏�܂Ƃ߂��Ă���A���������ƂɈ��q�̌��ʂ����v�I�ɗL�ӂł��邩�ǂ����f���܂��B���U���͕\�͎�v�Z����ɂ͌v�Z�̐��m�����`�F�b�N���邽�߂̃c�[���Ƃ��ďd��Ă��܂������A���݂ł���͌��ʂ̉��߂�����ɕs���Ȗ������ʂ����Ă��܂��B�܂��A��A���͂ȂǑ��̓��v��@�ɂ����Ă��A���U���͕\�͉�͌��ʂ�v��`���Ƃ��ė��p����邱�Ƃ������ł��B���̂悤�ɁA���U���͖@�̓f�[�^�̕ϓ������q��덷�Ƃ������v�������ɕ����鎋�_����A���q�̌��ʂv�I�Ɍ��肷�邱�ƂŁA�Ȋw�I�Ȍ��_���菕�������܂��B���̂��߁A���U���͖@�𐳂������������p���邱�Ƃ́A���v��͂�����v���������Ŕ��ɏd�v�ł��B
�֘A�L��

![]() �y�g�b�v�y�[�W�֖߂�z
�y�g�b�v�y�[�W�֖߂�z![]() �yYouTubeChannel�z
�yYouTubeChannel�z![]() �y���v��͍u�`��b�z
�y���v��͍u�`��b�z![]() �y���v��͍u�`���p�z
�y���v��͍u�`���p�z![]() �yChatGPT�EPython�EExcel�z
�yChatGPT�EPython�EExcel�z![]() �y���ϗʉ�́z
�y���ϗʉ�́z![]() �y��Ó��v��́z
�y��Ó��v��́z







