
�ꌳ�z�u�@�ň��q�̉e����O���́I�y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z

�ꌳ�z�u�@�́A����̈��q�̉e���ׂ邽�߂̎����v��@�ł���A���q�̐�������J��Ԃ����ɐ����͂Ȃ��B���ϓ������q�ԕϓ��ƌ덷�ϓ��ɕ��������U���͂��s�����Ƃň��q�̌��ʂ����肷��B���̕��@�ł͎����������_���ȏ����ōs���A�f�[�^��K�ɐ����E�ϊ����Čv�Z����B���U���͕\�̍쐬�ɂ͏C������ϓ��A���R�x�Ȃǂ����߂�菇�ށB��Ƃ��āA4�l�̕��͒S���҂̕��͒l�ɍ������邩�ׂ�����ł́A�v16��̃����_���Ȏ�����ʂ��ĕ��U���͂����{�B���ʁA���q�Ԃ̗L�Ӎ����F�߂��A�S���ҊԂŕ��͒l�ɈႢ�����邱�Ƃ����������B���̎�@�́A���q�̉e���m�ɂ��邽�߂̗L���ȓ��v��͖@�ł���B
![]() ����������������
����������������
�`�����l���o�^�͂�����
�ꌳ�z�u�@�̓��v�w
�ꌳ�z�u�@�̎����́A��������l�ɑ��āA�P�̈��q�̉e���ׂ����Ƃ��ɗp�����܂��B
���������āA���̌v���p�����ʂ́A
�@�v���̒�����������x�i��ŁA�c�����傫�Ȉ��q�ɂ��Ẳe���ׂ����Ƃ�
�A�����̗v���̌��ʂ�����ƍl�����邪�A��Â��݂ɂ���P�̈��q�̉e���ׂ����Ƃ�
�Ȃǂł��B
���̌v��̎����ł́A���q�̐������A�e�������Ƃ̌J��Ԃ����ɂ͓��ɐ����͂���܂���B
������̏ꍇ�ł��A���̌v��̃f�[�^�U���͂���ɂ́A��{�I�ɂ́A���ϓ������q�ԕϓ��ƌ덷�ϓ��ɕ������Č��肷�邱�ƂɂȂ�܂��B
�J��Ԃ��������̏ꍇ
���̌v��̎����ł́A�Ƃ�グ�����q�̊e�������Ƃɓ����̂���Ԃ��������s���ăf�[�^���Ƃ��܂��B
��ʂɁA���qA�ɂ��Ă��������Ƃ�A�e�������Ƃɂ��̌J��Ԃ����v�悵���ꌳ�z�u�@�̎����ł́A�\�̂悤�ȃf�[�^�������܂��B

���̏ꍇ�A�S�����̓����_���ȏ����ōs���̂������ł���A���̂��ߗ�����p���Ď������������肵�܂��B
���U���͂̕��@
���P
���܁A���͉ۂɂS�l�̕��͒S���҂����܂��B
���̊e�S���҂̕��͒l�ɍ������邩�ǂ����ׂ邽�߁A�W�������ꑕ�u�Ŋe�S�J��Ԃ��ĕ��͂����邱�ƂƂ��܂����B
�v16��̎����̓����_���ȏ����ōs���A���\�̂悤�ȃf�[�^�܂����B
�e�S���҂̕��͒l�ɈႢ�����邩�ǂ�����������B
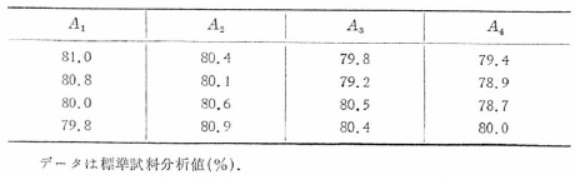
���̗��́A�����������S�A�J��Ԃ��������S�̈ꌳ�z�u�@�ɂ������ł��B
�ȉ��A���̃f�[�^���ɂƂ��ĕ��U���͂̎菇�������܂��B
���U���͂̎菇
�菇�P�@���f�[�^�̃O���t��
���f�[�^���O���t�ɕ\���A���q�̌��ʂ̊T����c�����܂��B
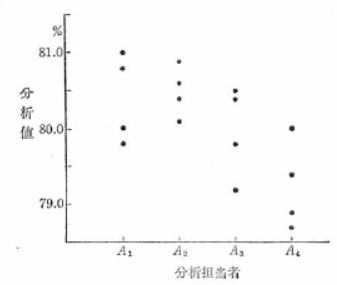
���̐}���A�e���͒S���҂��Ƃɂ��Ȃ�̕��͌덷���F�߂��܂����A����ȏ�ɕ��͎ҊԂɑ傫�ȍ�������悤�ł��B
���̍��v�I�Ɍ��肷�邽�߁A�ȉ��̉�͂��s���܂��B
�菇�Q�@���f�[�^�̏W�v
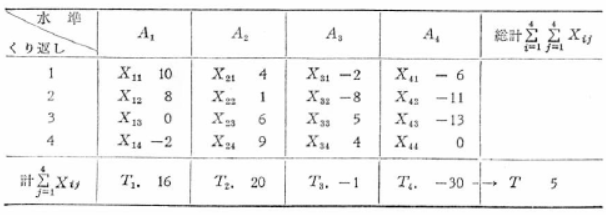
���f�[�^�ɂ��āA�e�����̌v�A���v�A����ё����ϒl�����߂܂��B
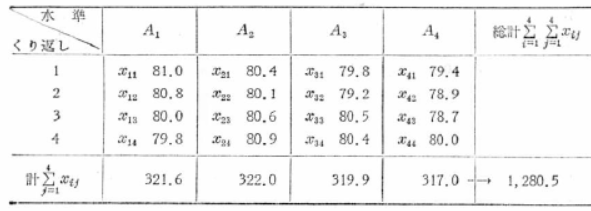
�Ȃ��A���̌��ʂ͎菇�R�ɂ����錴�f�[�^�̐��l�ϊ��̃`�F�b�N�ɗp������A�e�����̕ꕽ�ς̐���̍ۂɗp�����肵�܂��B
�����ϒl�F

�菇�R�@���f�[�^�̊ۂ߂ƕϊ�
�v�Z���ȒP�ɂ��邽�߁A���f�[�^�̊ۂ߂ƕϊ����s���܂��B
�@ ���f�[�^�̕ϓ��������Q�`�R���ɂȂ�悤�ɉ��ʂ���ۂ߂�
�A �ۂ߂��f�[�^�����萔�i�Ȃ�ׂ������ϒl�ɋ߂����E���h�E�i���o�[�j�������A�f�[�^�������ɂȂ�悤�ɊȒP�Ȑ����i100, 10, 5, 2�Ȃǁj���|���܂��B
�܂�A�ϊ���̃f�[�^�͎��̎��̂悤�ɂȂ�܂��B
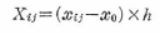
���̃X�e�b�v�́A�݂��ɂǂ�����ɂ���Ă��\���܂���B
���̗��P�͌��f�[�^�̕ϓ��������Q���ł���A���������ćA�̐��l�ϊ��݂̂��s���悢���ƂɂȂ�܂��B
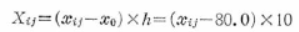
���̕ϊ��̌��ʂ��܂Ƃ߂�ƁA�ȉ��\�̂悤�ɂȂ�܂��B
�ϊ���́A�ϊ��f�[�^���瑍���ϒl�����߁A��Ɍ��f�[�^���狁�߂������ϒl�Ɣ�r���āA�ϊ��Ɍ�肪�Ȃ����`�F�b�N���܂��B
�ϊ��f�[�^���狁�߂������ϒl�́A
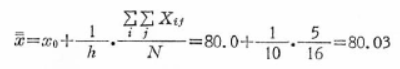
���f�[�^���狁�߂������ϒl�́A
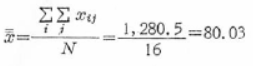
���҂͈�v���Ă��܂��B���������āA�ϊ��ɂ͌�肪�Ȃ����̂ƍl�����܂��B
�Ȃ��A���f�[�^���ϊ���K�v�Ƃ��Ă��Ȃ��ꍇ�́A���f�[�^�\��\�̂��Ƃ������ĂĈȌ�̌v�Z���s���܂��B

�菇�S�@�⏕�\�̍쐬
�ϓ��̌v�Z�ɕK�v�ƂȂ�ϊ��f�[�^�̓��\���쐬���A���v�����߂܂��B

�菇�T�@�ϓ��̌v�Z
�C�����icorrection factor, ������CF�j�����߂܂��B

���ϓ�S�����߂܂��B
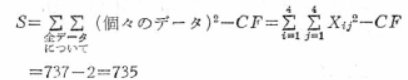
���qA�̐����ԕϓ�SA�����߂܂��B

�덷�ϓ�SE�����߂܂��B
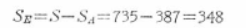
�Ȃ��ASE�����߂�ʖ@�Ƃ��ẮA

�ƂȂ�܂��B
�菇�U�@���R�x�̌v�Z
�e�ϓ��̎��R�x�����߂܂��B
���ϓ��̎��R�x�F
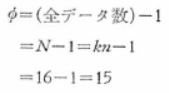
���q�̐����ԕϓ��̎��R�x�F
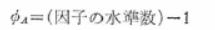
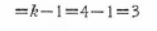
�덷�ϓ��̎��R�x�F
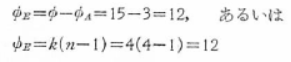
�菇�V�@���U���͕\�̍쐬
�菇�T�A�U�ŋ��߂��ϓ�����ю��R�x���A�ȉ��\�̂悤�Ȍ`���̕��U���͕\�ɂ܂Ƃ߂܂��B
���f�[�^��ϊ��̂����v�Z���Ă���ꍇ�́A�ϊ������Ƃɖ߂����ߊe�ϓ���1/h2���悶�Ă��番�U���͕\���L�����܂��B
���̗��P�ł́A�e�ϓ���1/h2=1/100���悶�Ă���\���쐬���܂����B

s.s.�Fsum of square�@�������a�A�ϓ�
d.f.�Fdegree of freedom�@���R�x
m.s.�F�@mean square�@���ϕ����A�s�Ε��U
Fo�F���ϕ����i�s�Ε��U�j�̔�B�ϑ��l���狁�߂��l�Ȃ̂ŁAobserved value�i�ϑ��l�j��o������B
��\�̌��ʂ���A���qA�̊e�����Ԃ̕ϓ��ɂ��āA
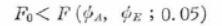
�Ȃ�ΗL�Ӎ��Ȃ��A
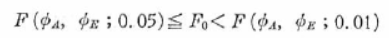
�Ȃ�ΗL�Ӑ���5%�ŗL�Ӎ�����Ɣ��肵�āA���U���͕\����Fo�̐��l�̉E���ɐ��������B
�܂��A
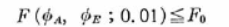
�Ȃ�A�L�Ӑ���1%�ŗL�Ӎ�����Ɣ��肵�āA���U���͕\���̉E���ɐ�������܂��B
���̔���@��}������ƈȉ��̂悤�ɂȂ�܂��B
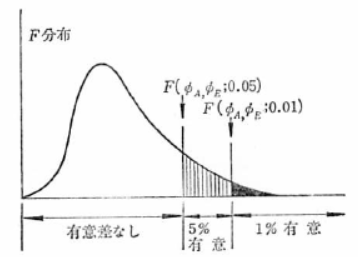
���̗��P�ł́A
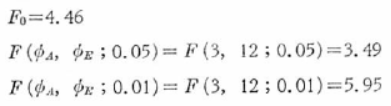
���������āA
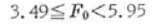
���Ȃ킿�A���q�̐����Ԃ̕ϓ��́A�덷�ϓ��ɑ��ėL�Ӑ���5%�ŗL�Ӎ����F�߂��܂��B
���̌��ʁA�S�l�̕��͒S���҂ɂ́A�W�������̕��͒l�̏o�����ɍ������邱�Ƃ��F�߂��܂����B

�ꌳ�z�u�@�́A���v�w�ɂ����镪�U���͂̈��@�ł���A����̈��q���������ʂɗ^����e���𖾂炩�ɂ��邽�߂̊�{�I�Ȏ����v��@�ł��B���̕��@�ł́A��̈��q���̐����ő��삵�A���̈��q�̐����ԂŌ��ʂɈႢ�����邩�����肵�܂��B���q�̐�����������̌J��Ԃ��ɂ͐������Ȃ��A�����҂������̖ړI�ɉ����ď_��ɐݒ肷�邱�Ƃ��ł��܂��B�����f�[�^�����W������A���ϓ������q�ԕϓ��ƌ덷�ϓ��ɕ������A���ꂼ��̕��U���v�Z���邱�Ƃň��q�̌��ʂ����肵�܂��B�ꌳ�z�u�@�̊�{�I�ȍl�����́A���ʂ̂�����ǂ̒��x���q�ɂ��e���Ő����ł��邩�𑪂邱�Ƃɂ���܂��B���̂Ƃ��A���q�̌��ʂ��L�ӂł��邩�ǂ����f���邽�߂ɁA���U���͂�p���܂��B���U���͂ł́A�܂����ϓ��i�S�̂̃f�[�^�̂���j���A���q�ɂ��ϓ��i���q�ԕϓ��j�Ƃ��̑��̗v���ɂ��ϓ��i�덷�ϓ��j��2�ɕ������܂��B���̕ϓ������̊�b�ƂȂ�̂����U���͕\�ł���A���U���͕\�ɂ͏C������ϓ��A���R�x�A�����a�A���ϕ����AF�l�Ap�l�Ȃǂ��܂܂�܂��B�����̎w�W���v�Z����菇�Ƃ��ẮA�܂��S�Ẵf�[�^�_�̍��v����C�������v�Z���A�������ɕ����a�����߂܂��B���ɁA���R�x���l�����ĕ��ϕ������Z�o���A�ŏI�I��F�l���v�Z���܂��B����F�l�����v�I�ɗL�ӂł���ꍇ�A���q�̌��ʂ��L�ӂł���Ɣ��f�ł��܂��B�ꌳ�z�u�@�̓K�p��Ƃ��āA4�l�̕��͒S���҂ɂ��f�[�^�̂���ׂ�P�[�X���l���܂��B���̎����ł́A�e�S���҂����͂�4�J��Ԃ��A�v16��̎������s���܂��B�f�[�^���W��A�������ʂ������_���ȏ����Ő������A���U���͂����{���܂��B��̓I�ɂ́A�e�S���҂̕��͒l�̕��ϒl���v�Z���A�������Ɉ��q�ԕϓ������߂܂��B����A�e�f�[�^�_�����̃O���[�v�̕��ϒl����ǂ̒��x����Ă��邩����Ɍ덷�ϓ����v�Z���܂��B���U���͕\���쐬���AF�l��p�l���v�Z���邱�ƂŁA�S���ҊԂɓ��v�I�ɗL�ӂȍ������邩�����肵�܂��B���̗�ł́A���͂̌��ʁA���q�ԕϓ����덷�ϓ�������A�S���ҊԂŕ��͒l�ɗL�ӂȍ������邱�Ƃ����炩�ɂȂ�܂����B���̂悤�ɁA�ꌳ�z�u�@�́A����̈��q�����ʂɗ^����e���m�ɂ��邽�߂̗L���Ȏ�@�ł��B���̎�@�̓����́A�����������_�������邱�ƂŊO���v���̉e�����ŏ����ɗ}����_�ɂ���܂��B�����_�������ꂽ�����v�́A�������ʂ̕��h���A���M�����̍������_�����߂̏d�v�ȃv���Z�X�ł��B�܂��A�ꌳ�z�u�@�́A�����̏����i�K�ň��q�̉e�����ȒP�Ɍ����邽�߂ɓK���Ă���A���G�Ȏ����v��̊�b��z�����߂ɂ����p����܂��B����ɁA���̎�@�͂��܂��܂ȕ���ʼn��p����Ă���A�Ⴆ�A���番��ł͈قȂ鋳���@���w���̊w�͂ɗ^����e���ׂ������A��Õ���ł͈قȂ鎡�Ö@�̌��ʂ��r��������Ȃǂɗp�����Ă��܂��B�ꌳ�z�u�@�����ʓI�Ɋ��p���邽�߂ɂ́A�f�[�^�̑O����������Ă��邩�ǂ������m�F���邱�Ƃ��d�v�ł��B�Ⴆ�A�f�[�^�����K���z�ɏ]�����Ƃ�A�e�O���[�v�̕��U�����������ƂȂǂ��O��ƂȂ�܂��B�����̑O���������������Ă��Ȃ��ꍇ�A���ʂ̐M���������Ȃ���\�������邽�߁A���O�Ƀf�[�^���m�F����K�v������܂��B�܂��A�����v��i�K�ŏ\���ȃT���v�������m�ۂ��邱�Ƃ��d�v�ł��B�T���v���������Ȃ��ƁA���v�I����͂��ቺ���A���q�̌��ʂ����������X�N�����܂�܂��B���������āA���O�ɕK�v�ȃT���v���T�C�Y���v�Z���A�K�Ȏ����v��𗧂Ă邱�Ƃ����߂��܂��B�ꌳ�z�u�@���w�сA���H���邱�ƂŁA�����҂̓f�[�^��͔\�͂����コ����ƂƂ��ɁA�������ʂ̉��߂ɂ����Ă��q�ϓI�Ȕ��f���������Ƃ��ł���悤�ɂȂ�܂��B����ɁA���̎�@�𑼂̕��U���͎�@�Ƒg�ݍ��킹�邱�ƂŁA��蕡�G�Ȉ��ʊW����͂��邱�Ƃ��\�ƂȂ�A�����v��@�̉��p�͈͂��L���邱�Ƃ��ł��܂��B
�֘A�L��

![]() �y�g�b�v�y�[�W�֖߂�z
�y�g�b�v�y�[�W�֖߂�z![]() �yYouTubeChannel�z
�yYouTubeChannel�z![]() �y���v��͍u�`��b�z
�y���v��͍u�`��b�z![]() �y���v��͍u�`���p�z
�y���v��͍u�`���p�z![]() �yChatGPT�EPython�EExcel�z
�yChatGPT�EPython�EExcel�z![]() �y���ϗʉ�́z
�y���ϗʉ�́z![]() �y��Ó��v��́z
�y��Ó��v��́z







