
Excelソルバーで解き明かすPCAの秘密【東京情報大学・嵜山陽二郎博士のAIデータサイエンス講座】

Excelのソルバー機能を使うと、主成分分析(PCA)でデータの重要な特徴を簡単に抽出できます。この方法では、データを標準化し、相関係数の平方和を最大化することで、主成分得点、固有値、固有ベクトル、因子負荷量を計算します。固有ベクトルは最適なデータ変換の方向を、固有値はその方向の情報量を示します。因子負荷量は変数と主成分の関連性を表し、データセット内の総合指標と機能差の指標を明らかにします。ソルバーによるPCAは、複雑な数学的操作を必要とせず、Excel内で直接的、効率的にデータ分析を可能にします。
![]() ▼▼▼▼▼▼▼▼
▼▼▼▼▼▼▼▼
チャンネル登録はこちら
目次 Excelソルバーで解き明かすPCAの秘密【東京情報大学・嵜山陽二郎博士のAIデータサイエンス講座】
ソルバーによる相関係数の平方和の最大化
主成分分析では相関係数を最大化するという理屈は分かっても、どうやってそれを計算すれば良いのか難しいと思われるかもしれません。
しかしご安心ください。Excelには、ソルバーという便利なアドインツールがあります。
ソルバーを使えば、最大化も最小化も制約条件の設定も、自由自在に行うことができます。
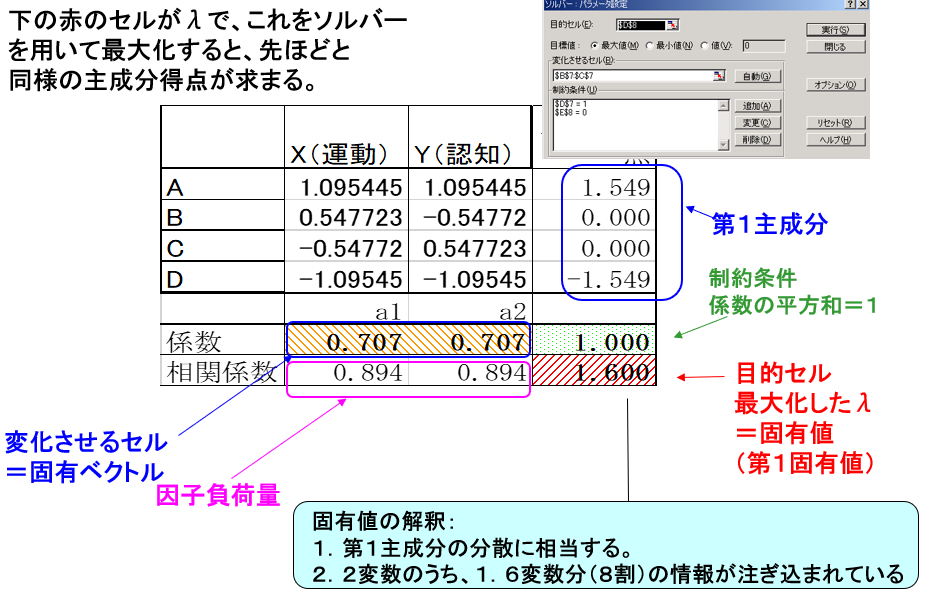
主成分得点・固有値・固有ベクトル・因子負荷量
Excelに表のようにデータを入力し、係数a1、a2(セルB7、C7)に適当な値を入れます。最初は0.5とかの適当な値で良いです。
セルB8には=CORREL(B$2:B$5,$D$2:$D$5)すなわちXと主成分得点との相関係数が入ります。
セルC8には=CORREL(C$2:C$5,$D$2:$D$5)すなわちYと主成分得点との相関係数が入ります。
D列は主成分得点で、セルD2には、=SUMPRODUCT(B2:C2,$B$7:$C$7) が入ります。
セルD7には、=SUMSQ(B7:C7) つまり固有ベクトルの平方和が入ります。これを1に固定するため、ソルバーの制約条件としてD7=1を設定します。
セルD8には、=SUMSQ(B8:C8) つまり相関係数の平方和が入ります。固有ベクトルを変化させながらこのセルD8をソルバーで最大化します。
D8(固有値)は1.6 と求まります。
因子負荷量は固有ベクトルに√1.6 を掛けることで求まります。X, Yそれぞれと第一主成分との相関係数をあらわします。
かくしてソルバー実行により、以下の値が得られます。
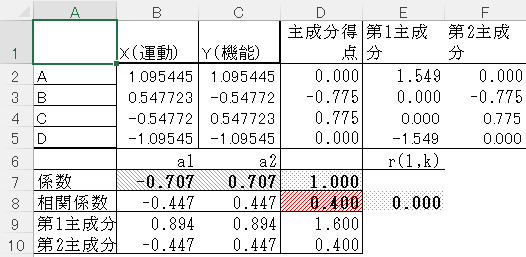
第1主成分 1.549, 0, 0, -1.549 ⇒ 総合指標
固有ベクトル 0.707, 0.707 ⇒ 主成分得点(X,Yの線形結合)の係数
固有値 1.6⇒ 情報量の指標(何変数分か)
因子負荷量 0.894, 0.894⇒ X,Yと第1主成分との相関係数

第2主成分は、第1主成分の計算で、第1主成分との相関が0であるというもう1つの制約条件をつけます。
まず、上記で求めた第1主成分をE列(E2:E5)に値コピーペーストします。
次に、セルE8に、=CORREL($D2:$D5, E2:E5) を入力します。制約条件E8=0をソルバーで設定します。
かくしてソルバー実行により、以下の値が得られます。
第2主成分 1.549, 0, 0, -1.549 ⇒ 機能差の指標
固有ベクトル -0.707, 0.707 ⇒ 主成分得点(X,Yの線形結合)の係数
固有値 0.4⇒ 情報量の指標(何変数分か)
因子負荷量 -0.447, 0.447⇒ X,Yと第2主成分との相関係数
かくして、主成分得点は固有ベクトルを係数とする以下の線形結合で表されます。
Z1 = 0.707X + 0.707Y
Z2 = -0.707X + 0.707Y
これを回転行列で表すと、
45度回転、つまり見た目と同じ結論になります。
相関係数行列の固有値問題
主成分得点の分散の最大値は固有値であるという話をしましたが、固有値というのは線形代数の用語で言えば、「相関係数行列の固有値」という意味です。
主成分得点の分散の最大値が相関係数行列の固有値であるという関係は、ラグランジュの未定乗数法と偏微分により得ることができます。
詳しくは線形代数の多変量解析の教科書を参照下さい。固有値問題と呼び、線形代数の教科書には必ず載っています。
主成分分析はExcelでは相関係数の平方和をソルバーで最大化することで実行することができます。
固有値、固有ベクトル、因子負荷量についても理解しましょう。
ChatGPTに聞いてみた
プロンプト
あなたは最高のデータサイエンティストです。
因子負荷量について解説してください。
#制約条件:
サルでもわかる平易な日本語で
文字数は300字程度
ChatGPTの回答
因子負荷量は、因子分析において、各変数がどれだけ因子に関連しているかを示す数値です。具体的には、変数と因子の間の相関を数値化したもので、その値が大きいほど、その変数は因子と強く関連していると言えます。たとえば、いくつかのテストの点数から「数学能力」「言語能力」という因子を抽出したとします。あるテストの点数が「数学能力」の因子負荷量が高い場合、そのテストは数学能力をよく反映していると考えられます。一方で、「言語能力」の因子負荷量が低ければ、そのテストは言語能力とはあまり関係がないことになります。簡単に言うと、因子負荷量は、変数が因子とどれだけ「仲がいいか」を示すスコアです。これにより、たくさんのテストやアンケートの結果から、本当に大切な情報を見つけ出すことができます。








