
F検定で解明!因子水準と特性値の関係【東京情報大学・嵜山陽二郎博士のAIデータサイエンス講座】

因子の水準を変えた場合に特性値に影響があるかを判断するには、因子間変動を誤差変動と比較します。具体的には、分散比によるF検定を用い、因子間の不偏分散(SA)と級内の不偏分散(SE)を比較します。SAは各水準の平均値の変動であり、誤差の影響も含まれるため、分子に適切とされます。自由度は、SAが水準数-1、SEが各水準のサンプル数-1の総和で求められます。全変動の自由度はデータ数-1で、これらの自由度の関係が成立します。有意水準1%でF検定を行うと、因子間の不偏分散が誤差変動を有意に上回る場合、因子の水準変更が特性値に影響を与えたと判断されます。
![]() ▼▼▼▼▼▼▼▼
▼▼▼▼▼▼▼▼
チャンネル登録はこちら
統計学における変動の比較
因子の水準を変えたことによって、特性値に影響があったか否かを判定するには、誤差変動に対して因子間変動の大きさを比較します。
すなわち、分離した級間のバラツキを級内のバラツキに対して検定すればよいことになります。
一般に、2つの変動を比較するには、それぞれの不偏分散を求めて分散比によるF検定を行うのが通例です。
そこで、この場合にも、2つの変動SA, SEに対してそれぞれの自由度を求め、不偏分散を計算してF検定を行えば、両者の比較を行うことができます。
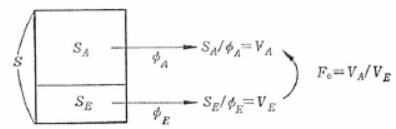
ここで、式からも明らかなようにSAは各水準の平均値の変動です。
いま、因子の水準を変えたことによる効果が全くないとしても、各水準の平均値は必ずしも一致しませんん。
これは、各水準の平均値が誤差の影響を受けているからです。
平均値自体、分散自体が誤差の成分を含んでいると考えます。
そこで、F検定を行う場合、因子効果と誤差の影響を含むVAと誤差の影響のみを表すVEとを比較するのであれば、直感的にVAを分子にする方がよいと考えられます。

さて、先ず総変動Sの自由度は、全体のデータ数Nから1を引いて、
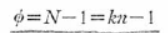
級間変動SAの自由度は、変化させる水準の数kから1を引いて、
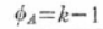
級内変動SEの自由度は、各水準ごとにn-1の自由度があるから、
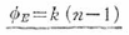
となります。
ここで、各自由度の間には、
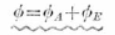
の関係が成立します。
不偏分散は、

したがって、
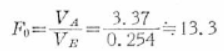
有意水準をα=0.01とすれば、
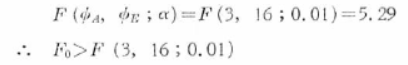
となります。
つまり、有意水準1%で、級間の不偏分散は級内の不偏分散に対して明らかに大きいと判定することができます。
因子の水準を変えた場合に特性値に影響があるかどうかを判断するためには、因子間変動を誤差変動と比較する必要があります。この比較の際に用いられるのが分散分析であり、その中でも特に分散比を用いたF検定が一般的です。F検定では、因子間の不偏分散(SA)と誤差の不偏分散(SE)の比を計算し、この比が統計的に有意であるかを検討します。因子間の不偏分散SAは、各水準ごとの平均値のばらつきをもとに算出されますが、このばらつきには因子の影響だけでなく誤差も含まれているため、分子に適しています。一方で、誤差変動を表すSEは、各水準内でのデータのばらつきを基準とします。これらの分散を比較することで、因子の水準変更が特性値に与える影響を評価します。自由度についても注意が必要で、因子間の自由度は水準の数から1を引いた値、誤差の自由度は各水準におけるサンプル数から1を引いた値の総和で表されます。これらは分母および分子の自由度としてF分布に基づく計算に利用されます。また、全変動の自由度はデータの総数から1を引いた値となり、これが因子間自由度と誤差自由度の和に一致することが理論的に保証されています。この関係は、分散分析の結果が正確であることを示すための重要な基盤となります。有意水準については、通常1%または5%のいずれかが選択されます。有意水準が1%でF検定を行う場合、計算されたF値が臨界値を超えると、因子間の不偏分散が誤差変動を有意に上回っていると判断されます。これにより、因子の水準変更が特性値に影響を与えたと結論付けられます。例えば、ある製品の特性値が異なる製造条件下でどの程度変化するかを検討する場合、これらの分析手法が有効に機能します。具体例として、製造工程で使用する温度が品質に与える影響を調べたい場合を考えます。3つの異なる温度条件で得られたデータを分析する際、各温度条件での平均値を比較し、それぞれの条件間に有意差があるかを評価することができます。この際、全データのばらつきを因子間変動と誤差変動に分解し、因子間変動がどの程度大きいかを判断します。計算されたF値が臨界値を上回る場合、温度が特性値に有意な影響を与えていると判断されます。反対にF値が臨界値を下回る場合は、温度の変化が特性値に対して統計的に有意な影響を及ぼしていない可能性が高いと解釈します。さらに、分散分析の前提条件にも注意が必要です。主な前提条件としては、データが正規分布に従っていること、分散が各水準で等しいこと、観測値が独立していることが挙げられます。これらの条件が満たされていない場合、分析結果の信頼性が低下する可能性があります。例えば、分散が等しくない場合にはウェルチの検定など別の手法を検討する必要があります。また、データの分布が正規分布から外れる場合は、データ変換やノンパラメトリック検定を採用することで対応可能です。このように、因子の水準が特性値に与える影響を正確に評価するためには、適切な手法とその前提条件への配慮が求められます。実験計画の設計段階でも、適切なサンプルサイズの選定が重要です。サンプルサイズが不足していると、分析の検出力が低下し、有意な結果が得られにくくなります。反対に、サンプルサイズが過剰になると、わずかな変動でも有意と判断される可能性が高まり、実際には意味のない結果に基づいた結論を導いてしまうリスクがあります。適切なサンプルサイズは、事前に期待される効果量と許容する誤差率に基づいて計算することが推奨されます。これらを踏まえると、因子の水準変更が特性値に与える影響を評価するプロセスは、単に統計的な計算にとどまらず、実験設計、データ収集、そして結果解釈までを包括する広範な取り組みであることがわかります。このような包括的な視点を持つことで、より信頼性の高い結論を導き出すことができるでしょう。
関連記事








