
�G�N�Z���ŊȒP! R2��Ō���\�����x�̐^���y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z

�ŏ����@�ɂ���A�W���̐���́A�c�������a���ŏ������邱�Ƃň�ӂɌ��肳��܂��B���̃v���Z�X��ʂ��āA�S�����a�i�S�ϓ��j�A��A�����a�i�������ꂽ�ϓ��j�A����юc�������a�i�������ϓ��j�̊W���m������A�����̘a�͓������Ȃ�܂��B���̊W����ɁA����W���iR2��j���v�Z����A�G�N�Z���̊���p���ĊȒP�ɋ��߂邱�Ƃ��ł��܂��BR2��́A���f�����f�[�^���ǂ̒��x�������Ă��邩�������w�W�ŁA�l��1�ɋ߂��قǁA���f���ɂ��\���̐��x���������Ƃ��Ӗ����܂��B
![]() ����������������
����������������
�`�����l���o�^�͂�����
�ڎ� �G�N�Z���ŊȒP! R2��Ō���\�����x�̐^���y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z
��A�W���Ɨ\���l�Ǝc�������a�̊W
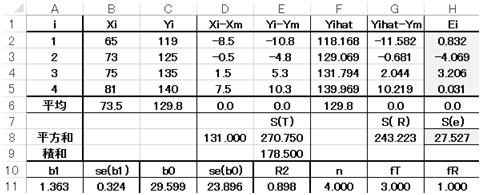
�ŏ��Q��@�̉��͈�ӂɌ��܂�̂ŁA�\���o�[�ɂ��ŏ��Q��@�œ���ꂽ�ω�������Z�������A�W���i�X���Ƃx�ؕЁj�����܂�܂��B
��������A�W����\�����ɑ�����邱�Ƃɂ��A���ꂼ��̗\���l�����܂�܂��B
���Excel�̃e�[�u���ł͂e���Yihat�Ƃ����̂��\���l�ł��B
�����āA�ϑ��l�x������\���l�����������̂��c���i�g��̂d���j�ł��B
�������SUMSQ�ŕ����a���v�Z�������ʂ��J����H8�ɕ\������Ă��܂��B
���ꂪ�c�������a�ł��B�����ł͒l��27.527 ��Ƀ\���o�[�Ōv�Z�������̂ƈ�v���Ă��邱�Ƃ��m�F���܂��傤�B
���������ƁA
�@�\���o�[�ʼn�A�W�������߂�
�A��A�W�������ɑ�����\���l�����߂�
�B�ϑ��l�Ɨ\���l�̍��i�c���j�����߂�
�C�c�������a�����߂�
�D�\���o�[�ŋ��߂��c�������a�ƈ�v���邱�Ƃ��m�F����
�����@�`�D�̎菇��Excel�V�[�g��ōs���Ă݂Ă��������B
������A�����̍l�����Ŋ����Ƃ邱�Ƃ��ł��܂��B
Excel�̗D�ꂽ�_�́A�Z���P�ʂŌv�Z��������̂Ōv�Z�ߒ��������ł��邱���ł��B
���v��p�\�t�g�̂悤�ɁA�����I�Ɍ��ʂ������o�͂����̂ƈ�����|�݂�����܂��B
���v��p�\�t�g�ł����s���A����ꂽ���ʂ���v���邱�Ƃ��m�F�ł���ƂȂ��ǂ��ł��傤�B

�S�����a����A�����a�{�c�������a
��A���͂͂����@�B�I�ɍs���̂ł͂Ȃ��A���s������A���͂̌��ʂ��Ó��ł��邩�ǂ������m�F���邱�Ƃ���ł��B
�m�F�����ő�Ȃ̂��A��A�f�f�ł��B
��A�f�f�ł́A���������f�f���v���ƌĂ����̂ɂ��]�����܂��B
�f�f���v�ʂɂ͐������̂��̂�����܂����A�����ł�����W���iR2��j�ɂ��ĉ�����܂��傤�B
���āA�悸������W���iR2��j�ł����A�q�Q��𗝉������ŕK�v�s���Ȃ̂��A�ȉ��̊W���ł��B
�S�����a�i�r�s�j����A�����a�i�r�q�j�{�c�������a�i�r�d�j
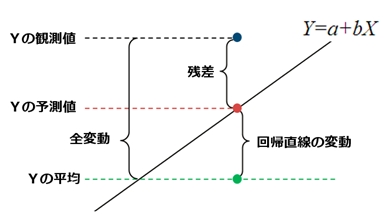
�悸�r�s�ł����A����͂x�̑S�ϓ���\���܂��B�x�̂S�̊ϑ��l���炻�ꂼ��x�̕��ϒl�x�������������̂̕����a�ł��B
�܂��߂Ɍv�Z���Ă��悢�ł����A�b��̂x����S�đI�����ADEVSQ�Ƃ������ɂ��ꔭ�Ōv�Z�ł��܂��B
�������r�q�ł����A����͉�A�����̕ϓ��A���Ȃ킿�w�Ƃx�̊W�ɋN������ϓ��ł��B
�����āA�r�d�͎c���i�덷�j�ɋN������ϓ��ł��B
�\���l�͂x�̕��ϒl�����������̂̕����a�ł��B�f��̒l��SUMSQ�Ōv�Z���܂��B
�}�̂悤���r�s���r�q�{�r�d�Ƃ����W�ƂȂ�̂ŁA
����W���iR2��j���G�N�Z���Ōv�Z
����W���iR2��j���r�q�^�r�s�@�ŕ\����܂��B
�܂�A����W���iR2��j�Ƃ͖ړI�ϐ��̑S�ϓ����̉�A�����̕ϓ��̊�����\���܂��B
�ȉ��̐}�̂悤�ɁA���ׂĂ̎c�����O�A���Ȃ킿�r�d���O�̂Ƃ��́A�r�s���r�q�ƂȂ�A�q�Q��͂P�ƂȂ�܂��B

�܂�AR2��Ƃ����̂́A�ϑ��l�������ɒ�����ɂ̂��Ă��邩�̎w�W�ł��B
�ɒ[�ȗ�ł́A�ϑ��l���ׂĂ������ɂ��傤�ǂ̂��Ă���ꍇ�A�r�d���O�ƂȂ�AR2��͂P�ɂȂ�܂��B
�ڈ��Ƃ��āAR2��͂O�D�V�ȏオ�ǂ��Ƃ���Ă��܂��B�����ł�R2���0.898�ƂȂ��Ă���܂��B
R2��𗝉������ł́A�r�s���r�q�{�r�d�Ƃ����W����ł��B
R2��Ƃ����̂́A�ȒP�Ɍ����A�ϑ��l�������ɒ�����ɂ̂��Ă��邩�̎w�W�ł��B
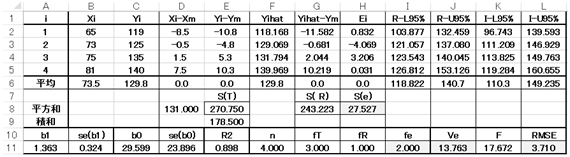
��L��Excel�e���v���[�g��������R2��̌v�Z���������Ă��܂��B
�������Excel�e���v���[�g���~�������͈ȉ����₢���킹�t�H�[�����烊�N�G�X�g������͍����グ�܂��B
ChatGPT�ɕ����Ă݂�
�v�����v�g
���Ȃ��͍ō��̃f�[�^�T�C�G���e�B�X�g�ł��B
R2��A����W���ɂ��ĉ�����Ă��������B
#��������F
�T���ł��킩�镽�Ղȓ��{���
��������300�����x
ChatGPT�̉�
R2��i����W���j�́A���v���f���̗\���̓��Ă͂܂���\�������ł��B0����1�܂ł̒l�����A1�ɋ߂��قǃ��f���̗\�����f�[�^�Ƀs�b�^�������Ă���Ƃ������Ƃ��Ӗ����܂��B�t�ɁA0�ɋ߂��Ɨ\���̐��x���Ⴂ���Ƃ������܂��B�Ⴆ�A���Ȃ����F�B�ƃo�X�P�����āA���_��\�����郂�f����������Ƃ��܂��傤�B���̃��f����R2�悪0.9��������A���̃��f���͂��Ȃ萳�m�ɓ��_��\���ł�����Ă��ƁB�ł��A0.1��������A���̗\���͂��ĂɂȂ�Ȃ����Ă��ƂɂȂ�܂��B�ȒP�Ɍ����ƁAR2��́u���̃��f���A�f�[�^�ɂǂꂭ�炢�t�B�b�g���Ă�H�v���ĕ����ꂽ�Ƃ��̓����ł��B�l���傫���قǁA�u�߂�����t�B�b�g���Ă�I�v���Ă��ƁB������A���f�������Ƃ��́AR2�悪�����Ȃ�悤�ɂ�����ł��B
�֘A�����N

![]() �y�g�b�v�y�[�W�֖߂�z
�y�g�b�v�y�[�W�֖߂�z![]() �yYouTubeChannel�z
�yYouTubeChannel�z![]() �y���v��͍u�`��b�z
�y���v��͍u�`��b�z![]() �y���v��͍u�`���p�z
�y���v��͍u�`���p�z![]() �yChatGPT�EPython�EExcel�z
�yChatGPT�EPython�EExcel�z![]() �y���ϗʉ�́z
�y���ϗʉ�́z![]() �y��Ó��v��́z
�y��Ó��v��́z







