
�U�z�}�ʼn����������I�f�[�^�̔閧�y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z

�U�z�}�͋L�q���v�̋��͂ȃc�[���ł���A��ʂ̃f�[�^�Ԃ̊W����X�������o�I�ɖ��炩�ɂ��܂��B�Ⴆ�A���A�a���҂̐H�O�����l��HbA1c�l���v���b�g���邱�ƂŁA�����̊Ԃɐ��̑��ւ������邱�Ƃ������I�ɗ����ł��܂��B����ɁA�U�z�}�̓f�[�^�Z�b�g���̊O��l�̓���ɂ��𗧂��A�ُ�l��e�ՂɎ��ʂł��܂��B�܂��A�J�e�S���[�ϐ��������ɗp���邱�ƂŁA�قȂ�O���[�v�Ԃ̃f�[�^���z���r���A���ϒl�̍��ق�f�[�^�̕��U�����o�I�ɑ����邱�Ƃ��\�ł��B�U�z�}�̓f�[�^�̓�������ڂő����A���ʓI�ȃR�~���j�P�[�V�����c�[���Ƃ��Ċ��p�ł��܂��B
![]() ����������������
����������������
�`�����l���o�^�͂�����
�ڎ� �U�z�}�ʼn����������I�f�[�^�̔閧�y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z
�U�z�}�F�f�[�^�S�̂̓��������o�I�ɕ\��
�U�z�}�́A�L�q���v�̒��ł��d�v�Ȏ�@�̈�Ɉʒu�Â����Ă��܂��B
���������̃f�[�^�̋�����\�������ŗL���Ȏ�@�ł��B
���Ƃ��A�ȉ��͂Q�U�l�̓��A�a���҂���̐H�O�����l��HbA1c�̒l��\�Ŏ��������̂ł����A���̕\���牽��������ł��傤���B
�\�Ƃ����̂́A�f�[�^�����܂Ƃ߂�ŏ��̃v���Z�X�Ƃ��Ă͊m���ɏd�v�ł��B
�������A�����������\�����āA�����f�[�^�̓��������߂邩�Ƃ����ƁA����͂ƂĂ�����ł��B
�����ŁA�H�O�����l�������AHbA1c���c���Ƃ����A���ϐ��̂Q�����U�z�}���쐬���܂��B
����Ɛ}�̂悤�ɂȂ�܂��B
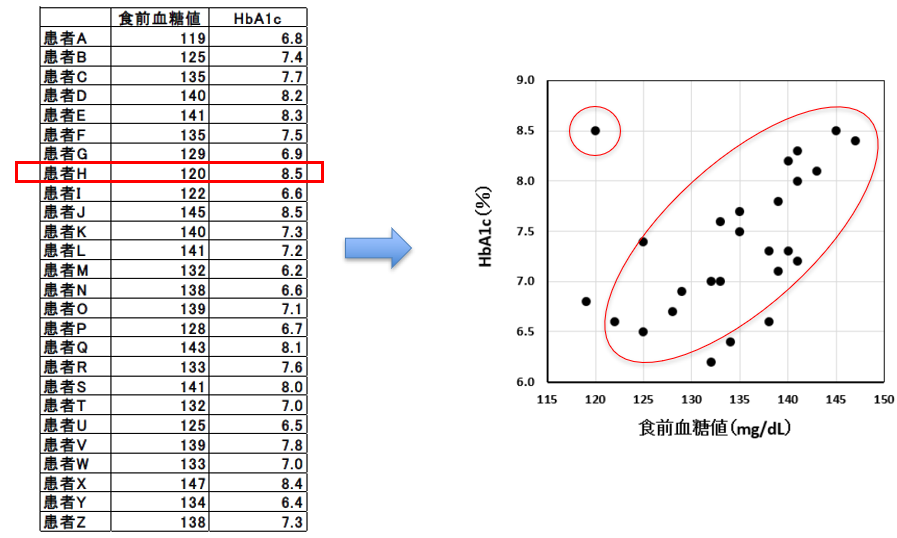
���̂悤�ɎU�z�}�ɂ���ƁA�\�ł͂킩��Ȃ������V���Ȕ����邱�Ƃ��ł��܂��B
���̗�̂悤�ɁA�e���҂ŐH�O�����l��HbA1c�̒l���P�������Ă���Ƃ��A���傤�ǎU�z�}�̂P�_���P�l�̊��҂ɑΉ����Ă��邱�ƂɂȂ�܂��B
�܂�Q�U�̓_���U�z�}�͕\������Ă��܂��B
���āA���̎U�z�}����ǂ̂悤�Ȕ�����������ł��傤���B
�悸�A�f�[�^�S�̂̋������A�E�オ��ɂȂ��Ă��܂��B
���v�w�̌��t�ł����ƁA���̑��ւ�����A�Ƃ����\���ɂȂ�܂��B

�U�z�}�F�O��l�̔����ɗL�p
���āA��������锭����������̂ł����A����͉��ł��傤���B
�H�O�����l�P�Q�O�AHbA1c�W�D�T�Ƃ����_���A�S�̂���O��Ă��邱�ƂɋC�����܂��B
�U�z�}�̈З͂Ƃ��āA
�@�f�[�^�S�̂̓��������o�I�ɗ������₷��
�A�O��l�����₷��
�Ƃ����_���������܂��B
�������J�e�S���[�ϐ��̎U�z�}
�ł́A�ȉ��̗�͂ǂ��ł��傤���B
���鑺�̊C���ɏZ��ł��鍂��҂ƁA�R���ɏZ��ł��鍂��҂ŁA�F�m�ǃX�P�[���̒l���r�������̂ł��B
�f�[�^�����邾���ł͂킩��ɂ����ł����A�Z��A�P�R�`B14�ɁA���ς��W�������v�Z����Ă��܂��B
���������ƁA���ς͊C���̕����Q�`�R�X�R�A�傫���A����͊C���A�R��������������x�ł���A�Ƃ������Ƃ��킩��܂��B
�v�v��������̂ŁA���ꂾ���ł��f�[�^�̓����͂킩��܂����A���̂悤�ȗ�ł��A�U�z�}���쐬����ƁA�f�[�^�S�̂̓��������o�I�ɂ킩��₷���������邱�Ƃ��ł��܂��B
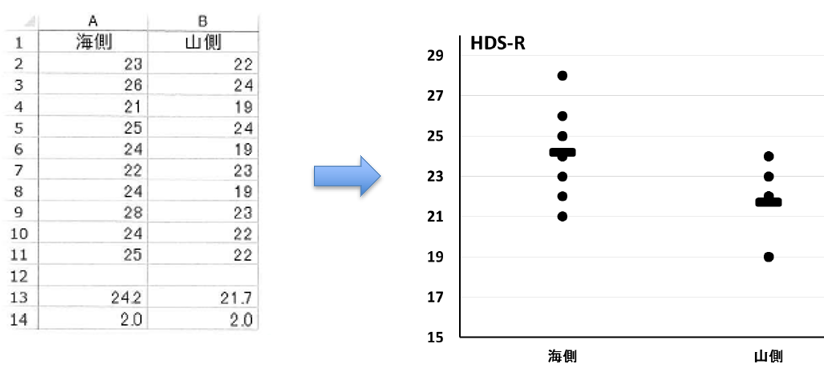
�����Q�����U�z�}�ł��A��̌����l�̃f�[�^�ƈقȂ�_�́A�������J�e�S���[�ϐ��i�C���A�R���Ƃ������A���l�łȂ��ϐ��j�ł��邱�Ƃł��B
���҂����ϒl�̍����R���x�A����͓����x�ł��邱�Ƃ��A�ЂƖڂł킩��܂��B
�������A���f�[�^�������Ď��o�I�ɔc���ł���̂ŁA�v�v�������̏ꍇ�ɔ�ׁA��������ʂ������ł��B
����������̎U�z�}�͍��̂����ʓ|�ł��B
Excel�ŎU�z�}����낤�Ƃ���ƁAXY����������ǂ����Ă����l�ɂȂ��Ă��܂��܂��B
����������̎U�z�}����邽�߂ɂ́A�悸�̓}�[�J�[�t���܂���O���t��`���āu�n��̏����ݒ�v�Łu���Ȃ��v�ɂ���쐬���邱�Ƃ��ł��܂��B
���̂悤�ɁA�U�z�}�͎��o�I�ɂ킩��₷���Ƃ����Ӗ��Ő����͂�����܂��B
�v�v���Ƃ��킹�āA�U�z�}�����p����ƁA�l�ɐ�������Ƃ��ɐ����͂�����܂����A�������������̂��y�ł��B����킩��ł��傤�A�Ƃ��������ł��B
��c�Ŏ����ɗ^����ꂽ���Ԃ��T�������Ȃ��A�Ƃ������ꍇ�A��c�̑O�ɖʓ|�ł��U�z�}���쐬���A�������c�Ŋ��p����ΒZ���Ԃŗ������Ă��炦��̂ŃR�~���j�P�[�V�����̃X���[�Y�ł��B
����A�U�z�}�����p���܂��傤�B
ChatGPT�ɕ����Ă݂�
�v�����v�g
���Ȃ��͍ō��̃f�[�^�T�C�G���e�B�X�g�ł��B
�U�z�}�ɂ��ĉ�����Ă��������B
#��������F
�T���ł��킩�镽�Ղȓ��{���
��������300�����x
ChatGPT�̉�
�U�z�}�Ƃ́A�Q�̈قȂ�ϐ��̊W�����o�I�Ɍ�����O���t�ł��B�Ⴆ�A�u�����ԁv�Ɓu�e�X�g�̓_���v�̊W�����������A�U�z�}���g���܂��B���̃O���t�ł́A�����Ɉ�ڂ̕ϐ��i�����ԁj�A�c���ɓ�ڂ̕ϐ��i�e�X�g�̓_���j��u���܂��B�����āA���ꂼ��̃f�[�^�_���v���b�g�i�_��łj���܂��B�f�[�^�_�S�̂�����ƁA�Q�̕ϐ��̊W����ڂł킩��܂��B�Ⴆ�A�_���E��Ɍ������ďW�܂��Ă���ꍇ�A�����Ԃ������قǃe�X�g�̓_���������Ȃ�X�������邱�Ƃ�������܂��B�U�z�}�́A�ϐ��Ԃ̊W�̋�����p�^�[����f�����c������̂ɖ𗧂��܂��B
�֘A�����N

![]() �y�g�b�v�y�[�W�֖߂�z
�y�g�b�v�y�[�W�֖߂�z![]() �yYouTubeChannel�z
�yYouTubeChannel�z![]() �y���v��͍u�`��b�z
�y���v��͍u�`��b�z![]() �y���v��͍u�`���p�z
�y���v��͍u�`���p�z![]() �yChatGPT�EPython�EExcel�z
�yChatGPT�EPython�EExcel�z![]() �y���ϗʉ�́z
�y���ϗʉ�́z![]() �y��Ó��v��́z
�y��Ó��v��́z







