
����ג��o�Ɩ�����̖��́F���v�Ǝ����̗����y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z

����ג��o�irandom sampling�j�́A���v�����ŕ�W�c���疳��ׂɃT���v����I�яo����@�ł��B�S�������ɔ�ׂĔ�p�Ǝ�Ԃ����Ȃ��A��\�I�ȗ�Ƃ��ăZ���T�X���������܂��B����ג��o�œ���ꂽ�T���v������̃f�[�^�́A��W�c�S�̂̌X���𐄑�����̂ɗp�����܂����A�G���[�}�[�W�������݂��A���ʂɂ͌덷������܂��B�܂��A������irandomization�j�́A�����ɂ����đΏۂ������_���Ɋ��蓖�Ă邱�ƂŁA���h�����߂̎�@�ł��B�ǂ�����m���Ɋ�Â����A�قȂ�T�O�ł��B
![]() ����������������
����������������
�`�����l���o�^�͂�����
����ׂ̓��v�w
����ג��o�irandom sampling�j
�ł��悭�m��ꂽ���v�I���@�̈�Ţ�����_���E�T���v�����O��Ƃ�������B
�����ף�Ƃ͍�ׂ��Ȃ��Ƃ����Ӗ��̓��{����A������random�͢�m���I����Ӗ��Ƃ���B
����o��́A�S�̂̑ւ��Ƃ��Ĉꕔ�𢒊���o���(�T���v�����O)���Ƃł���B
����ɂ�钲����T���v��������Ƃ����B
�ӂ��A��������{�l�́c�c��Ƃ����Ȃ���{�l�S��(��P��3�疜�l)�ׂĂ���łȂ��Ă͂Ȃ�Ȃ��A�ƍl����̂͗����ɂ��Ȃ��Ă���B
�������A����d������Q�����Ԃ̎��������飂Ƃ������i���̊Ǘ������邽�߂ɂ́A�������ꂽ�d�������ׂĂ��炩���ߎ����܂Ŏg�p���Ă݂�Ƃ����l�����́A�����I���낤���B
��������ł͂Ȃ��ł��낤�B
�����ʂ�A���Ƃ̏W�c(��W�c)�̂��ׂĂאs����������S��������Ƃ����B
���Ƃɒm����͎̂Љ��ΏۂƂ��铝�v����(�Љ��)�̂��߂̑S�������ŁA��Z���T�X�(census)�Ƃ���B
���Ƃ��Ƣ�Z���T�X��Ƃ�����́A�S�������̓T�^�ł��颍�����������Ӗ����Ă����B
�����܂ł��Ȃ��A�S�������͔���Ȕ�p(���������ł͐��S���~)�A����(�������T�N����)�A�����Ă����Ζ@�߂ɂ�鋭��(�������`��������)��K�v�Ƃ��A�N�ɂł��ł�����̂ł͂Ȃ��B
�i���Ǘ��ɂ����Ă��A�S�������͕s�\�Ƃ������͖��Ӗ��ł��邱�Ƃ������ł��낤�B
�S�������̂����ɂ����ƈ�����p�ŒN�ɂł��ł���₳�����������@�����̖���ג��o�ł���B
�𗧂ĕ�
�₳������������Ă݂悤�B
�܂���䒠������낦��B
��w�Ȃ�A����������w���ԍ��̂����w��������v�����B
�����āA�ڂ��Ԃ�Ȃ��烉���_����0-9�̐����ƂȂ��āA�S�����ƂɋL�^����B
�@�@�@2865�@�@0193�@�@3264�@�@8107�@�@5526
���̊w���ԍ���I�ׂ悢�B
�����5�l�̊w���������_���E�T���v�����O�ł����B
����Ȃ�A100�l�A500�l�A1000�l�A�c�c�ł��\�ł��낤�B
���ۂɂ͐���I�Ԃɂ͢�����\��A���邢�̓G�N�Z���̗��������v���O������p����B
�������Ƃ́A���̋K�������Ȃ��A�������m���ŕ���ł���0-9�̐��̗�������B
����ɂ���āA���Ƃ̕�W�c���ǂ�قǂ̐��ł��낤�Ƃ��A�ϓ��A�����ɁA���ՂȂ�(��裂Ȃ�)���Ƃ���1,000�l�𒊂��o�����Ƃ��ł���B
���̂悤�ɂ��ĂƂ���1000�l�̕����W�c��T���v���(�����_���E�T���v��)�Ƃ���W�{��Ƃ����B
�����_���E�T���v���͕�W�c�̒����ȏk�}�Ƃ����ׂ����̂ŁA�����_���E�T���v���œ���ꂽ�m���͂قڕ�W�c�̒m���ƍl���Ă悢�B
���̔��ʁA����ג��o�������ʂ�A���Ƃ̕�W�c���ׂ̂Ă���̂ł͂Ȃ����Ƃɂ͒��ӂ������邱�Ƃ͂Ȃ��B
�T���v���ł̐���(���Ƃ��Γ��t�x����)�́A��W�c�ł̂ق�Ƃ��̎x�����Ƃ͌����ɂ͂���Ă��āA��v���Ȃ��B
�����A���̕�W�c�x�����ɋ߂��x�������T���v���ɂ������(�T���v���x����)�����ł���A�V�����颓��t�x������͂���ł���B
������ق�Ƃ���(��W�c)�̓��t�x�����ł��邩�̂悤�Ɏv���͍̂��o�ł���B
�ق�Ƃ��̕�W�c�x�����͍����m�x(��M���W����Ƃ����邪�A�m���ŕ\��)�ŃT���v���x�����̋߂��ɂ���B
����ג��o�ɂ�����ꍇ�A�T���v���x������p(p�n�b�g�A�Ɠǂ�)�Ƃ��悤�B
���Ƃ��Ap= 0.45�Ȃǂł���B
���̂Ƃ��A��W�c�x�����̑��݂���͈͂́A�m��95���Ƃ���ƁA�ȉ���2��
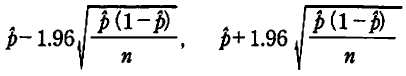
�̊Ԃł���B
n�̓T���v���E�T�C�Y(�T���v�����\������f�[�^�����̌�)�ł���B
������p=0.45�An=1000�Ƃ��Ă݂悤�B
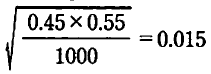
�䂦��1.96�~0.015 = 0.031(3%)�ŁA�ق�Ƃ��̎x������45�}3.1(��)�̊Ԃ܂�41.9%-48.1%�ł���i���̒��̂ǂ̐����͂킩��Ȃ�)�B
���́}3.1(%)��ג��o�̢�덷���(error margin)�Ƃ����B
���������ĐV���Ђ̓��t�x������ǂސ��������@�́A���̏ꍇ�ł́A�}3���̃G���[�E�}�[�W����t���ēǂނ��Ƃł���B
�c�O�Ȃ�����{�̐V���Ђ̓G���[�E�}�[�W���\���Ă��Ȃ��B
���A�T���v���E�T�C�Y��1000���x�Ȃ�R�����x�An��4000�Ƃ���Ɓ}1.5%�ƂȂ�B
���Ȃ킿�A���̕���n�̕������ɔ���Ⴗ��B
�܂��A����1.96�Ƃ����{���͐M���W��95���ɑΉ�����B
99���Ȃ�2.16�ƂȂ�B
��Љ���@����w�ڂ�
�����܂ł̗��_�́A�s�꒲���ɂ����p���邱�Ƃ��ł���B
�����̕���̂���ʓI�ł��킵�����@��葱�͢�Љ���@��Ƃ������@�Ƃ��Ēm���Ă���B
�����ג��o��ƂȂ��Ţ�������Ƃ����p�ꂪ���邪�A�S���ʂ̏p��ƍl���Ă悢�B

�����_���irandom�j
����ɂP�~��1000���Ţ�����_�����J�j�Y���
�����̒�����͂��܂��āA�Љ���̃T���v�����o��������_���E�T���v�����O��A����ɂ͐����I�V�~�����[�V�����ɗp���郂���e�J��������(�R���s���[�^����)�܂ŁA���ׂă����_���ł���B
������_����Ƃ͉����B
�P�~��1000�����W�߁A100�������ꂼ��0�A1�A2�A�c�c�A9�̐�����������A�����1000������̂���(����)�ɓ����B
���̂���𗼎�Ŏ����A�傫���㉺�ɉ�����U���āA�P�~�ʂ��悭�܂���悤�ɂ��A�P���Ƃ�o���A�ԍ����L�^����B
���ɂ܂������悤�ɂP���Ƃ�o���L�^����B
��������\�������Ԃ��ƁA���̗A
034743738636364 73661�c�c(�ȉ�����)
�̂悤�ɓ�����A�����ɓ���ꂽ�����̕��т͢�����(�����_���E�i���o�[)�A�܂������ݏo�����̂悤�Ȏd�g�݂͈�ʂɢ�����_���E���J�j�Y����A������_���@�\��A���邢�͢�����_���E�f�o�C�X��Ƃ�����B
�����_���@�\�ɂ́A���̂ق��A���̒�����@�A20�ʑ̢̂���������(��20�ʑ̂̊e�ʂ�0�A1�A2�A�c�A9���Q�������܂�Ă���)�R���s���[�^�̗��������R�}���h�Ȃǂ�����B
���g������N��͂����̏ܕi���������ŗ������g���邱�Ƃ͂������A�Љ���ł͗����ʼn҂�I�ԂȂǁA�����⌤���ŗp�����Ă���B
����K����Ƃ�������
������_���E���J�j�Y����Ƃ����邽�߂̍Œ�����͎��̂Q�ł���B
�@�Ɨ����@�e��̐��̏o�������̉�ȍ~�ɉe����^���邱�Ƃ͂܂������Ȃ��B
�A��l���z�@0�A1�A2�A�c�A9�͓������o���̊m��1 /10�����B
�����@�A�A�̐��������킹�Ģ�����_����̏����Ƃ����B
�Ɨ����@�ɂ��A����₻��ȍ~���m��I�ɗ\�z����(�������Ă�)���Ƃ͂ł��Ȃ����Ƃ͂������A��l���z�̐����A�ɂ��A�����������o�₷�����邢�͏o�ɂ����Ƃ����m���I�ȗ\�z���ł��Ȃ��B
�m��I�ɂ��m���I�ɂ��\�z�̕��@���邢�͋K��(���[��)�͂Ȃ��Ƃ������ƂŁA�v����ɢ�����_����Ƃ͢���K����̂��Ƃɑ��Ȃ�Ȃ��B
���K���Ȃ̂����碏o�₷���X����Ƃ��������͑��݂����A�\�ʓI�Ȣ�X��������ɂ��ƂÂ��ēq���ŏ��¢�헪������肦�Ȃ����Ƃɒ��ӂ��悤�B
�����͂ق�Ƃ��Ƀ����_�����@
������̐����̕��т������_�����A�Ɩ��ɂ���邱�Ƃ�����B
�ق�Ƃ��͢�����_������Ƃ����₢�̓����_���E���J�j�Y���ɑ�����̂ŁA�������P�ʂ�̌��ʂ������_�����ǂ����́A�����邱�Ƃ��ł��Ȃ��B
���ہA�������ƂɈقȂ��������������ʂ肠�蒲�אs�������Ƃ͂ł��Ȃ��B
�Ƃ͂����A����ꂽ���̕��т��瓝�v�f�[�^���͂�p���Ă����悻�̌������邱�Ƃ͂ł���B
���̓��v�I�Ȍ��́A���̃�2(�J�C�Q��)�̌v�Z��1 /10�Ƃ����z��(�e20��)����̂���𑪂���@�ł���B
�f�[�^�͗���������200��̌��ʂł���B
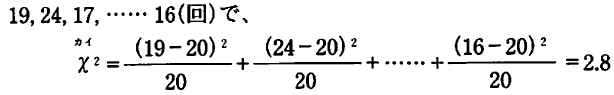
���̒l�͏������l�ł���B
���邢�͓��v���_�ł͢����͗L�ӂłȂ���Ƃ����B
���̍����͊�l16.92��菬��������ł���B
���̂悤�ɂ��āA�A�̏����̓N���A�����B
�@�̓Ɨ����v�I�Ɍ����邱�Ƃ́A�قƂ�Ǎs���Ă��Ȃ��B
����͇@���������Ȃ��p�^�[���͖����ɂ��肦�邩��ŁA�����(�ے��)�`�F�b�N�͕s�\������ł���B
�����ς烉���_���̍����ɏ\�����ӂ��邱�ƂŊm�F�����B
���̂Ƃ��A����̃p�^�[�������ڂ��������ƂŃ����_���łȂ��A�ƌ��_�Â��邱�Ƃ͂ł��Ȃ��B
���Ƃ��ΐ�̂���ɂP�~�ʂ̃����_���@�\�ł��A37-38�̑��������A63696��3�̔{����5��A���A���������̌��W�ɂ�83-84�A640-641�Ȃǂ��o�Ă���B
�ނ��뢑��������͋N�����Ă͂Ȃ�Ȃ���Ƃ���ƁA���ꂱ�����K���ɂȂ��Ă��܂��B
������_����ɂ������ɂ́A�ȏ�̊�b�I�ȏ펯���K�v�ł���B
������irandomization�j
������_����Ƃ͢����הz����A��������t���(random assignment)�Ƃ������B
�����ף�Ƃ͢��ף���Ȃ��Ƃ������Ƃ��Ӗ����A�Ό��random������̂����A���Ƃ��Ă͏����ł�����m������Ƃ��������킩��₷���B
���̢�����_����𗝉�����ɂ́A��������A�R�C��(�d��)���v���o���Ƃ悢�B
���ꂼ��1. 2. 3. 4. 5. 6���邢�͕\(1�Ƃ���)�A��(0�Ƃ���)���m���I��(�����_����)�o���Ƃ��ɗp���Ă���B
���ƂɃR�C���́A����ꂪ���̂��Ƃ������A�����Ɍ��߂悤�Ƃ���Ƃ��A���邢�͂��܂�Ɍ��߂邽�߂̗v�f����������Ƃ��A�ŏI����Ƃ��ėp���Ă���B
������_����ɂ͂������������b�g������B
�w�i�̌����������Ă���
���̢�����_����ɂ͎��̂悤�ȗp����������B
�܂����̂悤�Ȏ��Ԃ��̂��Ȃ��������P�[�X���������Ƃ��悤�B
�y�P�[�X�P�z
����w�Z�ŐV��������@�������I�ɓ������鏀���Ƃ��āA�P�g�ɐV��������@�A�Q�g�ɂ͏]���̕��@�����{�����i�����łP�g������Q��A�Q�g��ΏƌQ��Ƃ���)�B
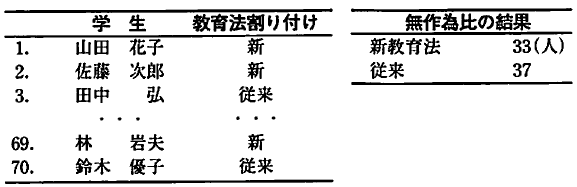
�P�g�̕����Q�g���]���e�X�g�̕��ς����������B
���̂��Ƃ���A�V��������@�ɂ͂������Ɍ��ʂ�����Ƃ����Ă悢���B
���́A���Ƃ��ƂP�g�̐��k�͂Q�ׂ̐��k���w�͂������������Ƃ����������B
�y�P�[�X�Q�z
�����t�͔F���ꂽ�V��̌��ʂ��m�F���邽�߁A�ߑO�̊��҂ɂ͐V��𓊗^(�����Q)�A�ߌ�̊��҂ɂ͏]���̖�𓊗^(�ΏƌQ)�����B�����Ԃ��̕��j�œ��^������A���Ì��ʂ�]�������Ƃ���A�ߑO�̊��҂̕����ǍD�Ȑ��т������Ă����B
���̂��Ƃ���A�V��͏]���̖�������Ì��ʂ��D��Ă���Ƃ����Ă悢���B
���́A���̈�Ë@�ւ͌ߑO���ɊO���A�ߌ�͓��@���҂�f�ÁE���Â��Ă���(�ȏ�́A���z��̐ݒ�Ō����Ƃ͖��W�ł���)�B
���̂悤�ȑ厸�s�͂悭����B
�����̃P�[�X�ł́A��������A�����Q�ƑΏƌQ���ŏ����瓯���̎��łȂ��A��������A�����E�����̖ړI�ł���V����@�̌��ʁA�V��̌��ʂ��A���ꂼ��V����@�̌��ʁ{�w�͍��A�V��̌��ʁ{�d�Ǔx�̍��A�Ƃ����悤�ɁA�w�i�̌������������Ă��܂��Ă���B
����𢍬����Ƃ���𗍣�Ƃ����B
���̂܂܂ł͖ړI�͉ʂ����Ȃ��B
�u�����_���v���𗧂�
�V����@�̌���(�P�[�X�P)�ŁA�P�g�A�Q�g�����ꂼ�ꔼ���Ɋ����āA�j�q���k���]���̋���@�A���q���k��V����@�ŋ����Ă݂�A�Ƃ����v���������邩������Ȃ��B
�������A���̃v�����ł́A����ǂ͊w�͂�K���̐���(���Ƃ��A����͏��q���k�̂ق����ł��邩������Ȃ��Ƃ������_���Ȃ��Ƃ�����Ȃ�)����������A�Ƃ����_�c���o�Ă���B
�����l����ƁA�����܂�ƒx���܂�A���邢�͑��̉Ȗڂ̊w�͍��A�d�d�d�Ɩ����Ɏ��X�ɗv��(�����̗v��)���l�����邱�ƂɂȂ�B
���������āA���錈�߂��v���ɂ���āA�����Q�ƑΏƌQ���邱�Ƃ͂ł��Ȃ��B
�R�C���Ń����_���Ɍ��߂���@�́A���̂�����̗v����������W�Ɍ��߂���̂ł���B
�����ŁA�P�[�X�P�ł́A�P�g�v���X�Q�g�̌v70�l���A���������R�C���𓊂��Č��߂�悤�ɁA�P�l�������Q�A�ΏƌQ�ɓ���Ă����悢�B
�P�[�X�Q�ł��A�����悤�ɃR�C���𓊂��Č��߂�悤�ɁA�����_���ɐV��𓊗^���銳�҂ƁA�]����𓊗^���銳�҂ɕ�����悢(�Ȃ��A��ÂŢ������Ƃ����Ƣ�l�̎�������v���o���ǎ҂����邾�낤���A�����ł̢�����Q��͂����܂œ��v�w�p��ł���)�B
��w�̕��ʂŗp�����Ă��邱�̖�����ɂ́A�����������A��C���t�H�[���h�E�R���Z���g����K�v�ł��낤�B
�������A���̕��@�ł͂Q�Q�͌����m���ɓ������Ȃ�Ƃ͌��炸(���E�\)�A����ɂ́A�Q�̌��ߕ�(�Q�ւ̊��蓖�ĕ�)�̓����_���ł��邪�A���ʂƂ��Ă̂Q�Q�͋��R�ɂP,�Q�g�̋�ʂ�j����ʂɋ߂�������Ă��邩������Ȃ��B
������̌��ʂ܂ł͕ۏ���Ȃ��A�Ƃ������Ƃ����ӂ��ׂ��ł���B
����ɂ́A���҂̗��ꂩ�炷��A�����ɗ��_�I�ɐ����ȕ��@�ł��낤�ƁA�����ɗ^�����鏈�u����t�̔��f�łȂ��A�m���I��(�܂�A�����������������R�C��������)���܂邱�ƂɁA�����A�Ƃ܂ǂ��A���f�������邱�Ƃ͔������Ȃ��B
����͂��Ƃ��A�C���t�H�[���h�E�R���Z���g�������Ă��ς��Ȃ��A�Ƃ����ᔻ���悹����B
����̑傫�ȉۑ�ł���B
�Ȃ��A��������Ƣ����ג��o��́A�Ƃ��ɢ�m��������Ƃɂ��Ă��邪�A�܂������قȂ������W�ȍl�����ł���B
�֘A�����N

![]() �y�g�b�v�y�[�W�֖߂�z
�y�g�b�v�y�[�W�֖߂�z![]() �yYouTubeChannel�z
�yYouTubeChannel�z![]() �y���v��͍u�`��b�z
�y���v��͍u�`��b�z![]() �y���v��͍u�`���p�z
�y���v��͍u�`���p�z![]() �yChatGPT�EPython�EExcel�z
�yChatGPT�EPython�EExcel�z![]() �y���ϗʉ�́z
�y���ϗʉ�́z![]() �y��Ó��v��́z
�y��Ó��v��́z







