
因子と誤差で解くデータ解析の鍵【東京情報大学・嵜山陽二郎博士のAIデータサイエンス講座】

実験データのバラツキを因子と誤差に分解することで、因子の影響を正確に評価できると考えられる。データの変動は偏差平方和で表され、総変動Sはデータと全体平均の差の平方和、因子間変動SAは各水準の平均値と全体平均の差の平方和、水準内変動SEは各水準内のデータとその平均値の差の平方和として定義される。これにより、データの総変動は因子の水準変動と水準内の誤差変動に分解される。統計解析では、この分解を利用することで因子の影響を合理的に評価できるため、データの構造を明確にし、分析精度を向上させることが可能となる。
![]() ▼▼▼▼▼▼▼▼
▼▼▼▼▼▼▼▼
チャンネル登録はこちら
統計学における変動の分解
実験によって得られたデータのバラツキが、もし因子や誤差の要因成分に分解することができるのなら、因子の効果を合理的に判定できるでしょう、と直感的に考えました。
はたして、データの変動をうまく分解することができるのでしょうか。
一般に、因子を1つとり上げた実験では、表のような形式のデータが得られます。

今、データの変動を偏差平方和(sum of squares)で表すとして、要因成分に分解することを検討してみましょう。
先ず、総変動Sは、個々のデータと総平均との差の平方和ですから、
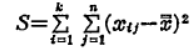
と表すことができます。
因子Aの水準間の変動、すなわち級間変動(SA)は、各水準の平均値が総平均に対してどのようにばらつくかで表せばよいですから、
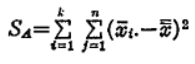
となります。
さらに、各水準内での変動、すなわち級内変動(SE)は、個々のデータが各水準の平均値に対してどのようにばらつくかで表せばよいですから、
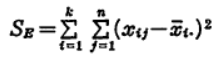
と定義することができます。そして、
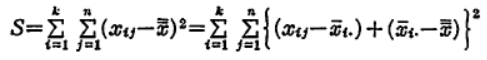
ここで右辺を展開すると、
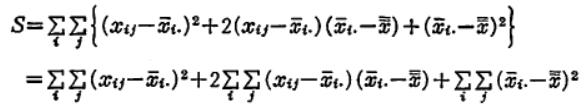
となります。しかるに、右辺の第二項は、
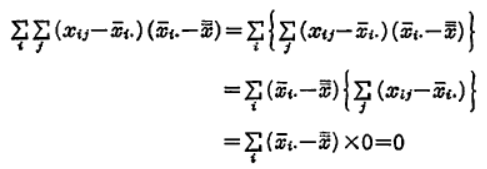
この結果を代入すると、
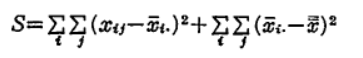
となります。よって、
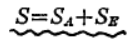
の関係となります。
すなわち、データの総変動が、因子の水準を変えたための変動、水準の中の誤差変動という2つの要因に分解できたことになります。
では実際に計算してみましょう。
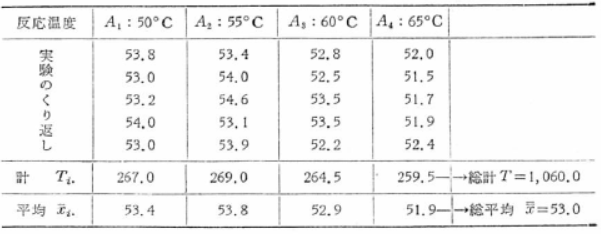

総変動Sは、
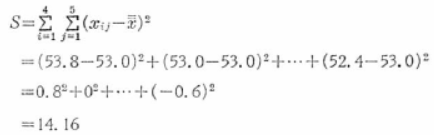
同様に、SAを求めると、

さらに、SEを求めると、

上式の関係から、
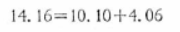
すなわち、
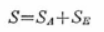
一般には、数字の丸めにおける誤差の範囲内で、上式が成立します。
実験データのバラツキを因子と誤差に分解することで、因子の影響を正確に評価できると考えられます。一般に実験では、因子の操作によって得られるデータには様々な変動が含まれており、その変動を詳細に分解することが実験計画法の基本的な目的の一つです。この分解において重要なのは、データの変動を偏差平方和(Sum of Squares)で表し、それを構成要素に分解することです。偏差平方和は、データと基準値(通常は全体平均)の差を二乗して足し合わせたもので、総変動Sとして表されます。総変動Sは、実験全体のデータが全体平均からどれだけばらついているかを示す指標であり、これが因子間の変動(SA)と水準内の誤差変動(SE)に分解されます。因子間変動SAは、因子の各水準ごとの平均値が全体平均からどれだけ離れているかを表しており、因子そのものがデータに与える影響を示すものです。一方、水準内変動SEは、同じ因子の水準内で各データがその水準の平均値からどれだけばらついているかを示します。これは主に誤差に起因するものであり、測定の不確実性や他の未知の要因による影響を含んでいます。このように、データの総変動を因子による変動と誤差による変動に分けることで、因子の効果を合理的に評価することが可能となります。この分解を行う際、統計解析では一般的に分散分析(ANOVA)が用いられます。分散分析は、変動の分解を数値的に検証する手法であり、分解結果に基づいて因子の影響が統計的に有意であるかどうかを判断します。この過程では、因子間変動と水準内変動をそれぞれ自由度で割ることで分散を求め、分散比(F値)を計算します。このF値を基にして、仮説検定を行い、因子が有意な影響を持つかどうかを検討します。このような変動の分解と解析により、データの構造を明らかにし、実験結果の解釈を合理的に進めることができます。例えば、新しい薬剤の効果を評価する実験では、薬剤の種類を因子とし、各被験者の反応をデータとします。この場合、薬剤の種類による変動が因子間変動に対応し、同じ薬剤を投与された被験者間の個人差が水準内変動に対応します。このような分析を通じて、薬剤の種類が反応に与える影響が統計的に有意であるかどうかを明確にすることができます。また、分散分析を活用することで、複数の因子が同時に存在する場合でも、それぞれの因子の影響や因子間の交互作用を解析することができます。これにより、実験デザインの複雑さに対応しながら、因子の影響を精密に評価することが可能になります。さらに、データの変動の分解は実験計画法だけでなく、品質管理や医療統計、社会科学など多くの分野で応用されています。この手法を活用することで、データのばらつきがどの要因によるものかを明確にし、対策を講じるための指針を得ることができます。例えば、製造業では生産プロセスの品質を管理するために因子分析を行い、製品のばらつきの原因を特定して改善を図ります。また、医療現場では患者データを解析して治療効果に影響を与える因子を特定することにより、効果的な治療戦略を立案することができます。このように、変動の分解は多様な応用分野において有用な手法であり、その理解と活用はデータ分析の基本的なスキルとして重要です。実際の実験では、因子の水準を慎重に設定し、適切な統計解析を行うことで、得られた結果をより信頼性の高いものとすることができます。また、解析結果を解釈する際には、分解された変動の比率や分散比の値だけでなく、背後にある実験デザインや測定プロセスの妥当性も考慮する必要があります。このような視点を持つことで、実験結果を適切に解釈し、実験計画の改善や新たな研究課題の発見につなげることが可能になります。以上のように、変動の分解はデータ解析の基礎でありながら、実験デザインや結果解釈において非常に重要な役割を果たしています。この手法を正確に理解し活用することで、より質の高いデータ解析が可能となり、科学的な発見や実践的な応用に貢献することが期待されます。
関連記事








