
一標本t検定で知る標本平均と母集団の違い【東京情報大学・嵜山陽二郎博士のAIデータサイエンス講座】

一標本t検定は、標本の平均と母集団の既知の平均を比較する際に使用されます。この検定では、帰無仮説として「標本と母集団の平均に有意差はない」と仮定します。例えば、鉛被曝が子供の知能に与える影響を調べる際、日本全体の5歳児の知能テスト平均が100点であることを知り、鉛被曝した15人の子供の標本を比較します。計算結果に基づいて帰無仮説が棄却されると、鉛被曝が知能に影響を与えた可能性が示唆されます。また、信頼区間を求めることで、母集団平均がどの範囲に入るかを推定できます。
![]() ▼▼▼▼▼▼▼▼
▼▼▼▼▼▼▼▼
チャンネル登録はこちら
一標本t検定とは
t検定の使い道の1つとして、標本の平均と母集団の既知の平均とを比較することがある。
この帰無仮説は普通「標本が引き出された母集団の平均と既知の平均との間に有意差はない」となる。
例えば、鉛被曝が子供の知能に与える影響を調べたいとする。
日本全体の5歳児の知能テストの平均点が100点だとわかっている。
そして鉛被曝したことがある15人の5歳児の標本がある。
この鉛被曝が彼らの知能に影響したかどうかがこのテスト結果に基づいてわかるかどうかを調べる。
知能指数は基本的にこの母集団では正規分布だとする。
すると帰無仮説は「鉛被曝をした子供のグループの知能指数と母集団全体の知能指数との問に差がない」ということになる。
両側検定を有意水準α=0.05で行う。
一標本t検定の計算
一標本1検定の式は以下のように表す。
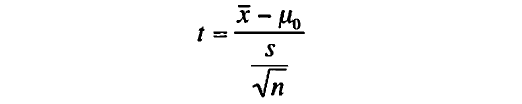
標本の平均と標準偏差を求める式を以下に表す。
標本平均の計算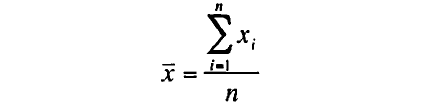
標本の標準偏差の計算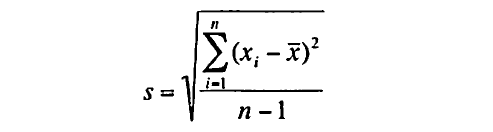
標本標準偏差を手で計算するのなら以下式がより簡単である。
標本標準偏差の計算しやすい式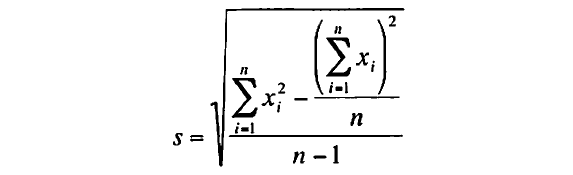
標本平均を90、標本標準偏差を10、標本数を15と仮定すると、t統計量は以下になる。
一標本t検定の計算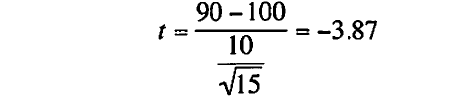
一標本t検定の自由度はn−1で、この例ではdf= 15-1 = 14となる。
t分布の上方棄却値の表より自由度=14、有意水準α = 0.05の両側t検定の上方棄却値は2.145になる。
先のデータのt統計量の絶対値が上方棄却値を上回るので(|-3.87| >2.145)、知能テストで、鉛被曝した子供の知能指数と母集団全体の知能指数が同じになるという帰無仮説は棄却される。
平均の差とt統計量が負であることから、鉛被曝した子供の平均知能指数は同年代の母集団全体の平均知能指数に比べて低いと言える。
一標本t検定の信頼区間
検定統計最や有意検定だけでなく信頼区間を求めたいときもある。
信頼区間は平均周辺の値の範囲であり次の意味を持つ。
同じ母集団から同じサイズの無数の標本を取ることができたら、x%の確率で母平均は標本から計算された信頼区問に入れる。
(最も一般的な) 95%で信頼区間を計算するとき、x = 95なので同じ母集団から取られた無限個の同じサイズの標本から計算された信頼区問は95%で真の母平均を含むと予想される。
より一般的にいうと、標本平均のような点推定の精密性に関する情報を信頼区間から知ることができる。
狭い範囲の信頼区間が、「異なる標本を取った場合でも、標本平均は取った標本にかなり近くなる」ということを暗示しているのに対して、広範囲にわたる信頼区間からは「異なる標本を取った場合に、標本平均は全く異なるかもしれない」ということがわかる。
一標本t検定の平均の両側信頼区間(CI)を求める式を以下に示す。
一標本t検定の信頼区間を求める式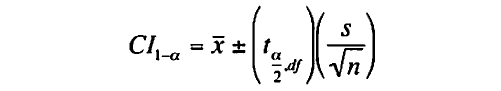
この例では、α= 0.05、x= 90、df= n - 1 = 14、s = 10、t= 2.145、n = 15である。
これらの数値を当てはめて以下式に示した結果を得る。
一標本t検定の信頼区間を求める式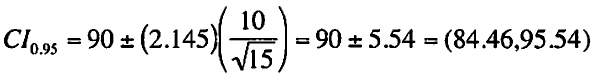
母平均の推測値の95%両側信頼区間は(84.46,95.54)になる。
この数値は信頼区間の下界・上界と呼ばれることもある。
この例では、下界が84.46で上界は95.54になる。
片側信頼区間を計算したい場合には、適当に正負を変えて、α/2ではなくαを使ってt分布の表から得た上方棄却値を使う。
異なるサイズの信頼区問を計算する場合には、適切な上方棄却値をt分布の表から選んで使う。
例えば、片側で、自由度(df) 20の90%信頼区問におけるtの上方棄却値は1.325になる。

関連リンク








