
t分布の秘密:正規分布に近づく理由とは?【東京情報大学・嵜山陽二郎博士のAIデータサイエンス講座】

t分布は、実データがとる確率分布であり、標準正規分布よりも裾野が広く、自由度が大きくなるほど標準正規分布に近づきます。t分布は、アイルランドのギネス醸造所で品質管理を担当していたウィリアム・シーリー・ゴセットによって導入され、彼が「スチューデント」という偽名で発表したことから「スチューデントのt分布」とも呼ばれます。t検定は、主に平均の差を検定するために使われ、特に標本数が少なく、母集団の標準偏差がわからない場合に有効です。標本が大きくなるにつれてt分布は標準正規分布に近づきます。ゴセットのt分布の研究は、推測統計の発展に大きく寄与し、分散分析の基礎にもなりました。
![]() ▼▼▼▼▼▼▼▼
▼▼▼▼▼▼▼▼
チャンネル登録はこちら
ゴセットとt分布
t分布はアイルランドのギネスの醸造所の品質管理を担当していた化学者ウィリアム・シーリー・ゴセット(William Sealy Gosset)によって導入された。
ゴセットはスチューデント(Student)という偽名記事でt分布を述べたので、t分布はスチューデントのt分布、t検定はスチューデントt検定とも呼ばれる。
t検定には主に3つの種類があり、それらはすべて平均の間の差異を検定し、帰無仮説が正しいとしたときには、その統計量の確率を決定するために、t分布とその検定統計量との比較をする。
2つのグループを使った一元配置分散分析(ANOVA)の手順は数学的にt検定と同値である。
しかし、t検定の方がよく使われている。
加えて、t検定のロジックを理解することによって、より複雑なANOVAのロジックを追いやすくなる。
推測統計学の基本は、実データ集合についての推測をするために、既に登場した確率分布を使うことである。
正規分布のように、t分布は連続かつ対称的である。
正規分布とは、t分布の形状が標本の自由度に依存するということが異なる。
自由度は変化する値の個数を意味する。
t分布の自由度は主としてその標本の数に影響される。
標本が大きいほど自由度が大きい。
ゴセットは現実のデータからt分布を開発した。
ギネスの醸造所で品質保証をしながら、限られた大きさの標本から全体を推測するという問題を解こうとしていた。
ゴセットの重要な点は標本平均からの区間内に、母集団の平均が位置する確率を決定する上で標本サイズの影響を観察したことにある。
平均の相違の検定のためにt分布を使う状況が2つある。
1つはおおよそ正規分布と思う母集団から小さな標本を取り出すとき、もう1つは母集団の標準偏差を知らず、その代わりとして標本の標準偏差を使うときである。
中心極限定理を使うには標本数が小さすぎ、そしてその標本を取った母集団が正規分布に従うと考えられなければ、代わりにノンパラメトリックな方法を使わなければならない。
以下の図を見ると、t分布は標準正規分布にほとんどそっくりだが、テールの厚みが異なり、標準正規分布より若干裾野の広い分布である。
4つのt分布(dfは自由度)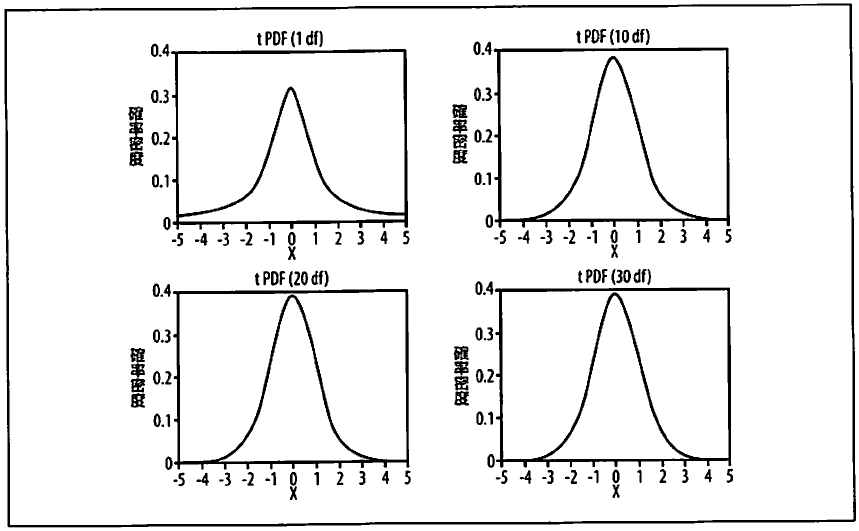
それはt分布の方が標準正規分布より極端な値も起きやすいということを意味している。
標本サイズが大きくなれば(したがって自由度が大きくなれば)、t分布は標準正規分布に似てくる。
標準正規分布に従う母集団から標本を抜き出し、標本標準偏差を使って母集団の分散を推定するとき、この母集団から取られたXの標本平均の分布は以下の関数で表現できることをゴセットは発見した。
t分布の関数
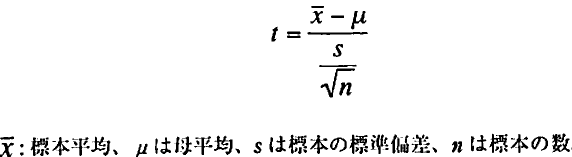
t統計量では標準偏差として母集団の標準偏差ではなく標本の標準偏差を用いるが、Z統計量では母集団の標準偏差を用いることだけが異なる。
t分布は対称的であるから、低い方の棄却値は必要ないので「上方棄却値」と言う(低い方はそれをマイナスにすればよい)。
正の値だけがt分布表に掲載されているから、両側t検定の棄却値を求めるためには、欲しい値の半分の値であるα値の列を使う。
α= 0.05の両側検定であれば、0.025の列を使う。
当然のことながら、標本が大きくなるにつれ、t検定の棄却値は標準正規分布の棄却値に近づく。
例えば、α= 0.05の両側検定の標準正規分布中の上方棄却値は1.96であるが、t分布を使ったα = 0.05の両側検定では、上方棄却値は自由度(df)に依存する。
1 dfでは上方棄却偵は12.706、10dfでは上方棄却値は2.228、30dfでは2.042、50dfでは2.009、100dfでは1.987、自由度無限大では1.96となる。
ウィリアム・シーリー・ゴセット
ウィリアム・シーリー・ゴセット(William Sealy Gosset)は、近代初の産業統計家と言われることが多い。
彼の功績の動機は勤務先(アーサー・ギネスSon&Co醸造所)の実用目的によるものだったが、彼が発見したt分布に基づいて一連の主要な推測統計検定ができたのは、彼の功績だ。
醸造所での問題解決との相関など関連手法を体系的に完成させたのち、彼は小さな標本の根本的な制限と多数の観察と実験で信頼性が得られるとした手法の限界を明らかにした。
ゴセットのt分布の研究は、R・A・フィッシャーによって開発された分散分析のような後の手法のもとになっている。
ゴセットの人生と功績は応用科学と理論展開の交互作用の素晴らしい実例を示している。

関連リンク








