
誤差と回帰:実測値と計算値の秘密【東京情報大学・嵜山陽二郎博士のAIデータサイエンス講座】

実測値 y と計算値 y-hat の違いを示す偏差 e は、実測値 y から計算値 y-hat を引いたものです。回帰モデルでは、実際の y の値は回帰直線の上下にばらつきがあり、誤差 e が加えられます。直線回帰モデル y=a+bx+e や、曲線回帰モデル y=a+bx−cx^2 が使われます。数学的モデルは、変数間の関係を数式で表現したもので、データに基づいて作られます。もし回帰直線からの偏差 e が大きければ、変数やモデル式を見直します。例えば、製品の味の評価のように、評価が中間点で最も高くなる場合には曲線回帰が適しており、価格と売上高の関係には指数関数式が適しています。これらのモデル式は、変数間の構造的な関係を示しています。
![]() ▼▼▼▼▼▼▼▼
▼▼▼▼▼▼▼▼
チャンネル登録はこちら
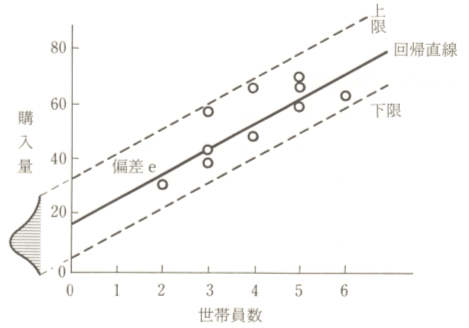
実測値と計算値の違い
回帰式yの値は、a+bxで計算した回帰直線上の値を示します。
実際のyの値には、回帰直線の上下のバラツキが加わります。
次の式中の記号eがそれで、誤差(error)として付け加えてあります。
y=a+bx+e
ただし、計算値と合わないから実際の値に誤差がある、というのは本末転倒でおかしいので、ここでは計算値からみたときの偏差と呼ぶことにしましょう。
そうすれば、
実測値y=計算値y-hat+偏差e
偏差e=実測値y−計算値y-hat
となります。
後の式の偏差eは、グラフでいえば、回帰直線上から各点に至る垂直距離です。
この偏差はプラス、マイナスに分布し、その平均値はゼロです。

数学的モデル
先に示した式、y=a+bx+e のように、実際に得られる変数間の関係を数式の形にまとめたものを、「数学的モデル」または「モデル式」と呼びます。
数学的ではなくて、文字や記号を用いてビジュアルに表現したモデルもあるので、「数学的」とことわっています。
モデルというのは本物に似せた模型ですが、全部似せれば本物と一緒になってしまいます。
だからある面だけ似ていればそれに関するかぎりモデルということができます。
プラモデルは外観というひとつの面が本物そっくりならいいわけです。
モデル式といった場合は、たとえばある商品の購入量と世帯員数の関係という面を似せて作ったもので、それが説明できればいいのです。
このモデル式は、黙っていても自然に与えられるというものではありません。
また、ある理論から必然的に導き出せるものでもありません。
分析者が変数を選び、実測データがある数式で表されるように工夫して作るものです。
もしうまくいかなければ、ほかの変数にかえたり数式を考えなおしたりして、また計算してみるという手順を繰り返します。
もし、原因とみなして取り上げた、ある変数でせっかく計算しても、回帰直線からの偏差eが大きくなるのであれば、また別の変数を探さなくてはなりません。
あるいは変数間の関係を直線的な1次式とするよりも、曲線的な2次式など別の形にしたほうがよさそうだという場合もあります。
直線回帰と曲線回帰
製品の味とその評価を考えた場合、味というものはほどほどがよいので、甘さでも辛さでも苦みでも、「ちょうどよい」という中間の点があるはずです。
評価はその点が最も高く、その両端では評価が低くなります。
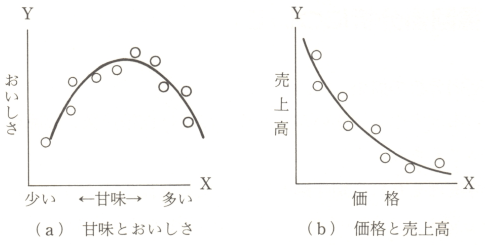
このような形も回帰の一つの形としてみることにして、曲線回帰と呼んでいます。
この傾向に適合するモデルとしては、1次式とは別の形を考えなければなりません。
それにはどんな式がよいでしょうか。どうして求めたらよいでしょうか。
左側のグラフにあてはまるモデル式としては、y=a+bx−cx2 のような2次式がよいでしょう。
この式では変数Xの値が大きくなると、変数Yの値は、式中のbxが効いて大きくなりますが、やがて−cx2がより効いてきて下降に転じます。
また、価格と売上高の関係では、価格をどんどん引き上げていくと、やがてその商品は全然売れなくなるでしょうから、右側のグラフのような曲線回帰が想定されます。
この右側のグラフにあてはまるモデル式としては、y=ab^x (bく1)のような指数関数式がよいでしょう。
変数Xの値は、係数bの指数の形でb^xとして組み込まれています。
この部分は、Xが大きくなるほど小さくなります。
しかし、決してマイナスになることはないから、グラフのような経過をたどって減少します。
この形は指数曲線と呼ばれよく用いられます。
このようなモデル式は、各変数がどのような構造によって結びついているかを示すものと考えればよいでしょう。
構造モデル、構造模型とも呼ばれているのはそのためです。
関連リンク








