
�m���p�����g���b�N�@�̔閧�FWilcoxon�Ƒ��d��r�@�y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z

�m���p�����g���b�N�@�idistribution-free methods�j�́A����̊m�����z�����肹���Ƀf�[�^�͂�����@�ł��BWilcoxon�̏��ʘa�����Wilcoxon�̕����t�����ʘa���肪��\�I�ł��B�Ɨ�����2�Q���r����ꍇ�AWilcoxon�̏��ʘa���肪�g���A�Ή��̂���f�[�^�̏ꍇ��Wilcoxon�̕����t�����ʘa���肪�p�����܂��B���Q���r����ۂɂ�Kruskal-Wallis���肪�p�����A����͈ꌳ�z�u���U���͂̃m���p�����g���b�N�łł��B���d��r�@�Ƃ��ẮABonferroni�@�AHolm�@�ATukey�@������A�����͕����̌Q�̔�r�Ő�����덷�����邽�߂Ɏg�p����܂��BBonferroni�@�͍ł��P���ŕێ�I�ł����A���o�͂��Ⴂ�Ƃ�������������܂��BHolm�@��Bonferroni�@�̊g���łŁA��荂�����o�͂������܂��BTukey�@�͑����̔�r���s���ۂɓK���Ă���A���o�͂��������@�ł��B���d��r�@�́A�����̌�����s���ۂ̌덷��������d�v�Ȏ�@�ł��B
![]() ����������������
����������������
�`�����l���o�^�͂�����
�ڎ� �m���p�����g���b�N�@�̔閧�FWilcoxon�Ƒ��d��r�@�y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z
�m���p�����g���b�N�@
�m���p�����g���b�N�@�idistribution-free methods�j�́A�f�[�^�̕��z�����K���z��t-���z�̂悤�ȓ���̊m�����z�����肵�Ȃ����@�ł��B
��ʂɃf�[�^�́A
�@�A���^�f�[�^�ł��邪���E�Ώ̂Ȑ��K���z�ɏ]��Ȃ��ꍇ�i���ɐ��̒l�����Ƃ�Ȃ��f�[�^�ŕW���������ςƓ����x�ȏ�̏ꍇ�A���z�̘c�݂����������j
�A���U�^�f�[�^�i��F�X�R�A�j�ł������K���z�Ƃ݂Ȃ��Ȃ��ꍇ
�Ȃǂ��������߁A�m���p�����g���b�N�@�����߂��邱�Ƃ������ł��B
�m���p������Ɨ�����邱�Ƃ�����܂��B
�Q�W�{t-�����A�Ή��̂���t-�����A�ꌳ�z�u���U�����ɑΉ�����m���p�����g���b�N����Ƃ��ẮAWilcoxon�̏��ʘa����AWilcoxon�̕����t�����ʘa����AKruskal-Wallis����̏����ʼn�����܂��B

�Ɨ��ȂQ�Q�̏ꍇ�FWilcoxon�̏��ʘa����
�f�[�^�ɐ��K�������藧���Ȃ��ꍇ�̃m���p�����g���b�N����Ƃ��āAWilcoxon�̏��ʘa����iWilcoxon�fs rank sum test�j������܂��B
���Ȃ݂ɁA�m���p������ł́A�f�[�^�̕��z�ɐ��K���z�Ȃǂ̓���̕��z�����肹���A��r����Q�ԂŃf�[�^�̕��z�̌`�����l�ł��邱�Ƃ݂̂����肵�܂��B
�ȉ��̗��̏ꍇ�AWilcoxon�̏��ʘa����́A22��̃f�[�^�ɏ��ʁirank�j�����A�Q�Q�̊Ԃŕ��Ϗ��ʂ��r���܂��B
���ʂ݂̂�p���邽�߁A�f�[�^�ɐ��K���̉��肪�s�v�ŁA�O��l�ɑ��Ċ挒���������܂��B
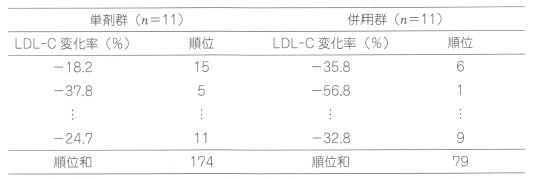
�ȉ��̕\�̓f�[�^�ɏ��ʂ��������̂ł���A����ł́A�P�܌Q�ƕ��p�Q�̏��ʘa�ł���174��79��ᐔ�Ŋ��������Ϗ��ʂ��r���܂��B
����̎菇�����Ɏ����܂��B�m���p������ł��菇��3 step�ł��B
���菇�P��
���L�̉������l���܂��i��������̂݉�����܂��j�B�����ŁA�͏��u�Q�ƑΏƌQ�̕��z�̈ʒu�i�Ⴆ�Β����l�j�̍��ł��B
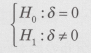
���菇�Q��
�Q�̌Q�̃f�[�^�S�̂ɑ��ď��ʁirank�j��t���܂��B
�����ʁities�j������ꍇ�ɂ͕��Ϗ��ʁi��F���ʂ��R�̃f�[�^���Q����ꍇ�́A���҂̏��ʂ�3.5�Ƃ���j�����܂��B
�f�[�^���牺�L��z���v�ʂ��v�Z���܂��B���̌��蓝�v�ʂ́AH0�̉��A�ߎ��I�ɕW�����K���z�ɏ]���܂��B
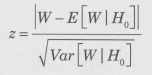
�����ŁAW�͏��u�Q�̏��ʘa�AE[W]�����Var[W]��W��H0�̉��ł̂��ꂼ�����������U�ł���A���u�Q�ƑΏƌQ�̃f�[�^����m�����n�Ƃ���ƁA�����Ōv�Z�ł��܂��B
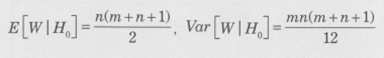
�Ȃ��A�����ʂ̃f�[�^�i�^�C�f�[�^�j������ꍇ�ɂ́A���ʘa�����U�ɏC�����K�v�ł��B
�o�l�̌v�Z����їL�Ӑ��̔���́AZ���v�ʂ��A�������̉��ŋߎ��I�ɕW�����K���z�ɏ]�����Ƃ𗘗p���āA�p�����g���b�N����Ɠ��l�ɍs���܂��B
Wilcoxon�̏��ʘa����́AMann-Whitney��U����Ɩ{���I�ɓ�������ł��邽�߁A�_����Mann-Whitney�����U����ȂǂƋL�q����邱�Ƃ����邪�A�S�ē����o�l�i���_�j��^���܂��B
�Q�W�{t-����̗Տ������f�[�^���AWilcoxon�̏��ʘa�����p���ĉ�͂��Ă݂܂��傤�B
���p�Q�im=11�j����ђP�܌Q�in=11�j�ɂ����铊�^�W�T���LDL-C�̕ω����i���j�̏��ʘa�́A���ꂼ��79�����174�ł��B
���̂Ƃ��AH0�F��=0��L�Ӑ���5%�Ō��肵�Ă݂܂��傤�B
�A�������i��=0�j�̉��ł́A���Ғl�����U�́A���ꂼ��A
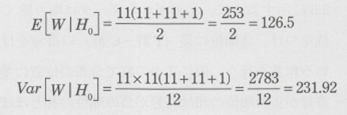
�ƂȂ�܂��B���������āA���蓝�v�ʂ́A
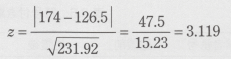
�ƂȂ��āAH0�̉��ŁA�y���v�ʂ͋ߎ��I�ɕW�����K���z�ɏ]�����߁A
P�l�i�y��3.119�ȏ�j��0.0018 �ƂȂ�AH0�͊��p����܂��B
����āA��W�c�ł�LDL-C�̕ω����̕��z�Ɋւ��āA���p�Q�ƒP�܌Q�̊ԂɗL�ӂȍ����݂��܂����B
�Ȃ��A���̗�̓f�[�^�̌`�����K���z�ɋ߂����߁A�Q�W�{t-����̌��ʁip=0.0007�j�Ƃقړ��l�̌��ʂł����B
���v�\�t�g�E�F�A�ɂ���ẮA���v�ʂ̌v�Z�ɂ����āA�A���ʂłȂ����ʘa�𐳋K�ߎ����邱�Ƃɑ������{���܂��B
���̏ꍇ�́A�y���v�ʂ̕��q�̐�Βl�̒����A���ʘa�|���Ғl�|1/2�Ƃ��邽�߁A�o�l����傫���Ȃ�܂��B
�Ή��̂���f�[�^�̏ꍇ�FWilcoxon�̕����t�����ʘa����
�Ή��̂���f�[�^��p���ĂQ�Q�̕��z���r����m���p�����g���b�N����́AWilcoxon�̕����t�����ʘa����iWilcoxon�fs signed rank test�j�ł��B
���̌���͑Ή��̂���t-����̃m���p������ł��B
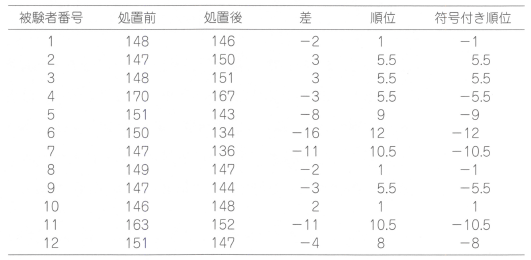
�����f�[�^�ł�����x�l����B�f�[�^�ɂ͑Ή������邽�߁A�팱�҂̒��łQ�̌Q�̍��iT�Q�|C�Q�j���Ƃ邱�Ƃ��ł��܂��B
���̂Ƃ��A�\�Ɏ����悤�ɁA�@����0�̃f�[�^�͎�菜���A�A���̍��́u��Βl�v�ɏ��ʂ����A�B���ʂɍ��iT�Q�|C�Q�j�̕�����t���A�����t�����ʂ����߂�Ƃ�����Ƃ��s���܂��B
���ɂQ�̌Q�ŕ��z�̈ʒu�ɍ����Ȃ��i���A�������j�Ȃ�A���������̏��ʂ̘a�͕��������̏��ʂ̘a�Ƃقړ������Ȃ�͂��ł��B
�����t�����ʘa����͂��̂悤�Ș_���Ɋ�Â�����ł���B�ȉ��Ɍ���菇�������܂��B
���菇�P��
���L�̉������l����i��������̂݉������j�B�����ŁA��T�ƃ�C�͂��ꂼ�ꏈ�u�Q�ƑΏƌQ�̕��z�̒����l�Ƃ��܂��B
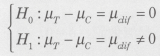
���菇�Q��
�e�̂ɑ��āA�Q�̌Q�̍��iT�Q�|C�Q�j���v�Z���A����0�͎̌̂�菜���܂��B
���́u��Βl�v�ɏ��ʂ�����B�����ʂ�����ꍇ�ɂ͕��Ϗ��ʂ����܂��B
���̏��ʂɍ��iT�Q�|C�Q�j�̕�����t���������t�����ʂ��v�Z���܂��B
���ɁA�f�[�^���牺�L�̂y���v�ʂ��v�Z���܂��B
���̌��蓝�v�ʂ͋A�������̉��A�ߎ��I�ɕW�����K���z�ɏ]���܂��B
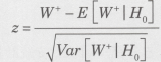
W+�͕��������̏��ʂ̘a�ł��B
![]()
��W+��H0�̉��ł̕���
![]()
��W+��H0�̉��ł����U�ł��B
�̐���n�Ƃ���ƁA�����Ōv�Z�ł��܂��B
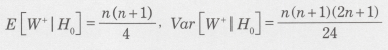
�Ȃ��A�^�C�f�[�^������ꍇ�ɂ́A���ʘa�����U�ɏC�����K�v�ł��B
���菇�R��
�o�l�̌v�Z����їL�Ӑ��̔���́A�y���v�ʂ��A�������̉��ŋߎ��I�ɕW�����K���z�ɂ����������Ƃ𗘗p���āA�p�����g���b�N����Ɠ��l�ɍs���܂��B
�\�̗Տ������̎��k�������̍��i���u�O�|���u��j�̕��������̂��̂̏��ʘa��W+=12�ł��B
���̂Ƃ��A�A��������L�Ӑ�������5%�Ō��肵�Ă݂܂��傤�B
�A�������i��0�j�̉��ł́A���Ғl�����U�́A���ꂼ��A
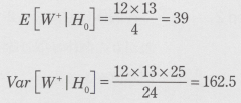
�ƂȂ�܂��B���������āA�y���v�ʂ́A
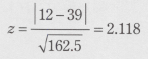
�ƂȂ�܂��B
H0�̉��ŁA�y���v�ʂ͋ߎ��I�ɕW�����K���z�ɏ]�����߁A�o�l�i�y��2.118�ȏ�j��0.034�ƂȂ�A���^�O��Ŏ��k�������������l�ɗL�Ӎ����݂��܂����B
�Ȃ��A���̗�ł́A�f�[�^�����K���z�ɋ߂����߁A�Ή��̂���t-����̌��ʁip=0.030�j�Ƃقړ��l�̌��ʂ������܂����B
���Q�̏ꍇ�FKruskal-Wallis����
�����ł́A�Ɨ��ȑ��Q�̕ꕽ�ς��r�����ꌳ�z�u���U�����ɑΉ�����m���p�����g���b�N����ł���Kruskal-Wallis�����������܂��B
�ȉ��Ɍ���菇�������܂��B
���菇�P��
�����͉��L�̂悤�ɂȂ�B�����ŁA��i�͕�W�c�ɂ������i�Q�������l�ł��B
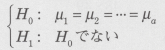
���菇�Q��
���̌Q�̃f�[�^�S�̂ɑ��ď��ʂ�����B�^�C������ꍇ�ɂ͕��Ϗ��ʂ����܂��B
�f�[�^���牺�L�̂g���v�ʂ��v�Z����B���̌��蓝�v�ʂ͋A�������iH0�j�̉��A�ߎ��I�Ɏ��R�x���|�P���J�C2�敪�z�ɂ��������܂��B
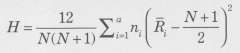
�����ŁA�m�͑��ᐔ�Ani�����Ri�͂��ꂼ���i�Q�̗ᐔ����ѕ��Ϗ��ʂł��B
�Ȃ��A�^�C�f�[�^������ꍇ�͕���K�v�ł��B
���菇�R��
�o�l�̌v�Z����їL�Ӑ��̔���́A�g���v�ʂ��A�������̉��ŋߎ��I�Ɏ��R�x���|�P���J�C2�敪�z�ɏ]�����Ƃ𗘗p���āA�p�����g���b�N����Ɠ��l�ɍs���܂��B
Kruskal-Wallis����́A�g���v�ʂ�p���邽�߂g����ƌĂ�邱�Ƃ�����B�܂��A�Q�̐����Q�̏ꍇ�AKruskal-Wallis�����Wilcoxon�̏��ʘa����Ɉ�v���܂��B
�ꌳ�z�u���U���͂̂Ƃ��Ɠ����f�[�^��p���ĉ�͂��܂��B
�v���Z�{�Q�in1=12�j�A�`��Q�in2=10�j�A�a��Q�in3=15�j�A�b��Q�in4=11�j�̓��^8�T���LDL-C�̕ω����i���j�̏��ʘa�́A���ꂼ��475, 247, 326, 128�ł���A���Ϗ��ʘa�́A���ꂼ��39.6, 24.7, 21.7, 11.6�ł��B
���̎��A�A��������L�Ӑ��������T���Ō��肵�Ă݂܂��傤�B
�g���蓝�v�ʂ́A
![]()
�ƂȂ�܂��B
H0�̉��ŁAH���v�ʂ͎��R�x�R���J�C2�敪�z�ɂ����������߁A
P�l�i��2��l��23.806�ȏ�j��0.0001�ƂȂ�AH0�͊��p����A�S�Q�ԂŁALDL-C�̕ω����������l�Ɋւ��L�ӂȍ���������܂����B
���Ȃ킿�A���^�Q�S�̂̌��ʂ͗L�ӂł����B
�Ȃ��A���̗�ł��A�f�[�^�����K���z�ɋ߂����߁A�ꌳ�z�u���U�����̌��ʂƓ��l�̌��ʂł����B
�܂Ƃ�
�@��W�c�̕��z�ɓ���̊m�����z�����肵�Ȃ����v��@�ł��B
�A�m���p�����g���b�N�@�̓f�[�^�����ʂɕϊ����������s�����߁A���ɊO��l�ɑ��Ċ挒�Ȏ�@�ł��B
���d��r�@�FBonferroni�@�EHolm�@�ETukey�@
�ꌳ�z�u���U�����́A�����̌Q�S�̂ɂ�����ꕽ�ς̍������o������̂ł��邽�߁A�ǂ̂Q�Q�̊Ԃɍ������邩�͂킩��܂���B
���̂��߁A��w�����ł́A�ꌳ�z�u���U������p�����Q�S�̂ł̕��ς̔�r�Ɠ��l�A���Q�̒��̂Q�Q�̃y�A�ŕꕽ�ς��r���邱�ƂɌ����̋��������邱�Ƃ������ł��B
���̎��A����i�Ⴆ�Q�W�{t-����j����s���ƁA�����ꂩ�̌���ő���̉ߌ낪������m�������ڂ̗L�Ӑ����i��F����5%�j�������傷�錟��̑��d���imultiplicity�j�̖�肪�����܂��B
�����ŁA���d��r�@�imultiple comparison procedure�j�Ƃ������d���̒����@���K�v�ƂȂ�܂��B
�}�̃x���}�́A����̑��d�������������̂ł��B
�R�̌X�̌���i��r�j�ő���̉ߌ낪������ꍇ�����ꂼ��R�̉~�ŕ\���ƁA�e�~�̎��ۂ�������m���͗�����=0.05�Ƃ��Ă��A�R�̌��肢���ꂩ�ő���̉ߌ낪�����鎖�ہi�R�̉~�̘a�W���j�̊m����0.05�������傷�邱�Ƃ��킩��܂��B
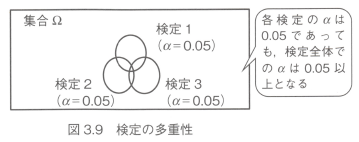
���d��r�@�̗p����ȉ��ɂ܂Ƃ߂܂��B
��̗�ł́A�R�̋A�����������肵�Ă��܂����A����S�̂ƍl���鉼���̏W����������family�ƌĂт܂��B
�����āA�������s���ہA������family�̒��ŁA�����1�ȏ�̋A�����������p����m�����AType 1 FWER�ifamily-wise error rate�j�ƌĂт܂��B
�����āA���d��r�@�Ƃ́A�X�̌���̗L�Ӑ��������āi�e����̃������������āj�AType1FWER�𗼑�0.05�ȉ��ɗ}������@�_�ł��B
���d��r�@�͑����̎�@����Ă���Ă��܂����A�����ł͘A���^�̕]�����ڂx�ɑ��āA�Q�W�{t-������p����ꍇ�̑��d��r�@�ɏœ_�Ăĉ�����܂��B
�܂��A�ł��P���ȕ��@�œK�p�͈͂��L�������o�͂��Ⴂ�i�����ێ�Iconservative�Ƃ����j��@�ł���Bonferroni�@�i�{���t�F���[�j�j���Љ�܂��B
�����ŁABonferroni�̊g���łł���Holm�@�i�z�����j���Љ�A�Ō��Tukey�@�i�e���[�L�[�j��Dunnett�@�i���l�b�g�j��������܂��B
Bonferroni�@
Bonferroni�@�́A�����k��s���ꍇ�A���̃x���}�̂悤�ɁA�e����̗L�Ӑ���������/k�ƒ���������@�ł��B
�Ⴆ�A������Q��s���ꍇ�A�����L�Ӑ�����0.025�ł���A�R��s���ꍇ�A�����L�Ӑ�����0.05/3=0.0167�ƂȂ�܂��B
���̂��߁ABonferroni�@�͌���̐��������Ȃ�ƌ��肪�L�ӂɂȂ�Â炭�Ȃ�A�ێ�I�Ȍ���Ƃ��Ēm���Ă��܂��B
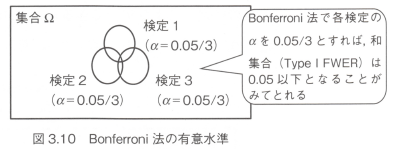
�܂��A��̉���ł͌���̗L�Ӑ�����������@�������܂������A���d��r�@�ł͌X�̌���̗����L�Ӑ�����0.05�Ƃ��Ăo�l������i�����ς݂o�l�ƌĂԁj���@������܂��B
Bonferroni�@�̒����ς݂o�l�́A
�����ς݂o�l���i�������o�l�j�~�i����̉��j
�ƌv�Z���܂��B
�������A�o�l�͊m���ł��邽�߁A�����ς݂o�l�͂P���Ȃ����̂Ƃ��܂��B
��w�_���ł͑��d��r�@��p����ꍇ�A�o�l��������̂��̂ł��邩�i�����ς݂܂��͖������j�L���邱�Ƃ��d�v�ł��B
�ꌳ�z�u���U���͂ŗp�������ɂ����āA�Ⴆ�S�Q�̒��̂��ׂĂ̂Q�Q�̑g�i�U�ʂ�j�ɑ��Ĕ�r���s���ABonferroni�@��p���đ��d���̒������s���Ă݂܂��傤�B
�ȉ��ɁASPSS��p���āA��L�̊e��r�ɑ��āABonferroni�@�Œ��������o�l���v�Z�������ʂ������܂��B
SPSS�̈ꌳ�z�u���U���͂̋@�\�̒��́A�u���̌�̌���v�ɂ����s�ł��܂��B
�����ŁA�Q�ϐ��igroup�j�́A�v���Z�{�Q���O�A�`��Q���P�A�a��Q���Q�A�b��Q���R�ŕ\����Ă��܂��B
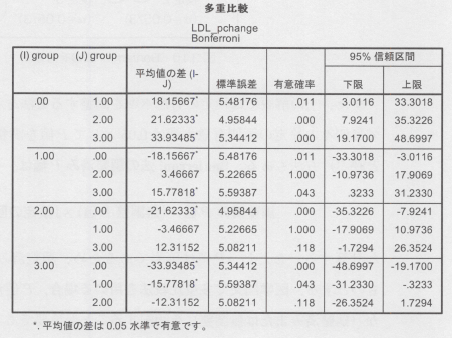
SPSS�̏ꍇ�A�o�͂̂R��ڂ̗L�Ӑ����́A�����ς�p�l�ł��邽�߁Ap��=0.05�̂Ƃ��ABonferroni�@�ɂ�錟�茋�ʂ͗L�ӂł���Ɣ��肵�܂��B
Holm�@
Holm�@��Bonferroni�@�̊g���łł��B
Bonferroni�@�����ׂĂ̌���Ŏ��O�Ɍ��߂��������L�Ӑ����i�Ⴆ�S����s���ꍇ�A��������0.0125�j��p����̂ɑ��āAHolm�@�͌X�̌��茋�ʁi�o�l�j�Ɋ�Â�����̋A����������בւ��A�����I�Ɍ���̗L�Ӑ�����ς��܂��B
���̂��߁AHolm�@�́Asequentially rejective���邢��step-down�菇�ƌĂ���@�ɕ��ނ���܂��B
����̎菇���ȉ��Ɏ����܂��B
�@�������o�l�����������ɋA����������בւ���
�AJ�Ԗڂ̋A��������L�Ӑ�����/k-j+1 �Ō��肷��B������k�͌���̐�
�B���肪�L�ӂłȂ��Ȃ�܂ŇA�𑱂���
�Ⴆ��k=5��̌�����s���ꍇ�A���\��j�Ԗڂ̌���̗����L�Ӑ�����Holm�@��Bonferroni�@�ɂ��Ď����܂����B
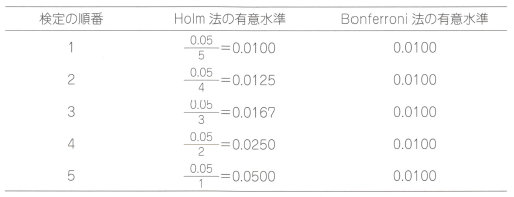
�ŏ��̌���ł́AHolm�@�̗L�Ӑ�����Bonferroni�@�̃��Ɠ������ł����A�Q��ڈȍ~�̌���ł͗L�Ӑ������傫���Ȃ邽�߁AHolm�@��Bonferroni�@�������o�͂������Ȃ�܂��B
�܂��AHolm�@�̒����ς݂o�l�́A�������Ă��Ȃ�P�l��j�Ԗڂ̌���̃��̕���ł���ik-j+1�j���|����悢�ł��B
�Ⴆ�T����s���ꍇ�A�P�Ԗڂ͂T�{�A�Q�Ԗڂ͂S�{�A�̂悤�Ɍv�Z���܂��B
Bonferroni�@�̍ۂ̗��Ɠ����U��̌���̑��d����Holm�@�ɂ�蒲�����Ă݂܂��傤�B
���茋�ʂ͈ȉ��ł���BHolm�@�́A�o�l�ŕ��בւ����㔼�̌���ł́A�����o�l���������o�l�Ɠ��l�ɂȂ邽�߁A���o�͂��������Ƃ��݂ĂƂ�܂��B
�����ł́AHolm�@�ł́A�a��Ƃb��̊Ԃ̍����L�ӂł��邪�ABonferroni�@�ł͗L�ӂłȂ��Ƃ������ʂɂȂ��Ă��܂��B
Tukey�@
Tukey�@�i���m�ɂ�Tukey-Kramer�@�j�́A���Q�̂��ׂĂ̂Q�Q�̑g�̔�r�Ɉ�w�I�ȊS������ꍇ�̑��d��r�@�ł��B
Bonferroni�@�̂悤�ɂ��ׂĂ̌���ɑ��ē����L�Ӑ�����p���܂��B
�Ⴆ�A����Տ�������10�̏��u�Q������ꍇ�A45�g��2�Q�̃y�A�̔�r���ׂĂɑ��đ��d��������̂�Tukey�@�ł��B
��ʂ�Tukey�@�ł͔�r�̐��������Ȃ邽�߁A���肪�ێ�I�ł��邱�Ƃ��m���Ă��܂����A�ȕւ�Bonferroni�@�Ɣ�r����ƌ��o�͂�������@�ł��B
Tukey�@�́AType1FWER�𖼖ڐ����i��=0.05�j�ɗ}����悤�ɑ��d�ϕ���p���Ċ��p���E�l���v�Z���A�o�l���v�Z���Ă��܂����A�ߔN�̓��v�\�t�g�E�F�A�ł͕W���I�Ɏg�p�ł����@�ƂȂ��Ă��܂��B
�Ȃ��ATukey�@�́AHonestly Significant Difference�iHSD�j�@�Ƃ��Ă�邱�Ƃ�����܂��B
�֘A�����N

![]() �y�g�b�v�y�[�W�֖߂�z
�y�g�b�v�y�[�W�֖߂�z![]() �yYouTubeChannel�z
�yYouTubeChannel�z![]() �y���v��͍u�`��b�z
�y���v��͍u�`��b�z![]() �y���v��͍u�`���p�z
�y���v��͍u�`���p�z![]() �yChatGPT�EPython�EExcel�z
�yChatGPT�EPython�EExcel�z![]() �y���ϗʉ�́z
�y���ϗʉ�́z![]() �y��Ó��v��́z
�y��Ó��v��́z







