
カッパ係数で解説!統計学的一致度の真実【東京情報大学・嵜山陽二郎博士のAIデータサイエンス講座】

統計学における一致の尺度は、評価者や検査の結果がどれだけ一致しているかを測定するための指標です。カテゴリーデータに対しては一致率が基本的な指標となり、評価の一致数を全体数で割って算出しますが、偶然の一致を考慮しないため限界があります。この問題を解決するために、コーエンのカッパ係数が用いられます。カッパ係数は偶然による一致を補正し、-1から1の範囲で結果を示します。1に近いほど一致度が高いことを意味しますが、カッパの妥当性については議論があり、特に偶然一致の計算に対して異論が出ています。
![]() ▼▼▼▼▼▼▼▼
▼▼▼▼▼▼▼▼
チャンネル登録はこちら
統計学における一致の尺度・カッパ係数
ここで示す種類の信頼性は、主に連続的な測定に役立つ。
カテゴリの判断に関心がある測定問題では(例えば、機械部品を許可可能や欠陥に分煩するなど)、一致の測定の方が適している。
例えば、疾患の有無を調べる2つの診断検査の結果の整合性を評価したい場合や、特定の生徒の教室での行動を許容可能か許容不可かに分類する3人の評価者からの結果の整合性を評価したい場合がある。
どちらの場合でも、評価者は限られた選択肢から1つの得点を与え、その得点が検査や評価者間でどの程度一致しているかが知りたい。
一致率(percent agreement, agreement note)は最も簡単な一致の尺度である。
一致率は、評価が一致した事例の数を評価総数で割って求める。
例えば、100個の評価を行い、評価が80%一致する場合、一致率は80/100(0.80)である。
簡単な一致率の欠点は、単なる偶然だけで高い一致度が得られる場合があることだ。
したがって、偶然で一致度が変わる可能性のあるさまざまな状況問で一致率を比較することは困難である。
この欠点は、コーエンのカッパ、カッパ係数、または単にカッパと呼ばれる別の一般的な一致尺度を使うと克服できる。
この尺度は、もともと2つの評価者や検査を比較するために考案され、より多くの評価者で使えるように拡張されてきた。
カッパは偶然による一致を補正するため、一致率より望ましい(しかし、統計家はこの補正が実際にどれくらい成功しているかに関して議論している。)

カッパは、以下表に示すように回答を対称な格子に並べて計算を行えば簡単に求められる。
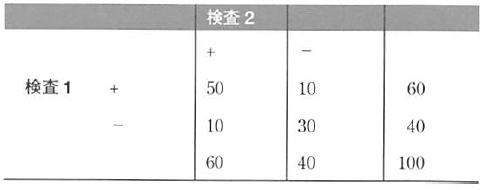
この例では、疾患のあり(D+)となし(D-)に関する2つの検査の一致度を調べたい。
データが入った4つのセルは、一般的に次のように分類される。
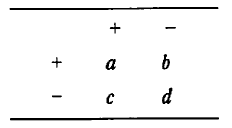
セルaとdは一致を表し(aには両方の検査で疾患ありと分類された事例が、dには両方の検査で疾患なしと分類された事例が入る)、セルbとcは不一致を表す。
カッパの式は次のようになる。
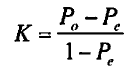
ここで、Po=実測一致率、Pe=期待一致率である。
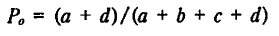
つまり,一致した事例数を事例総数で割る。
この例の場合は次のようになる。
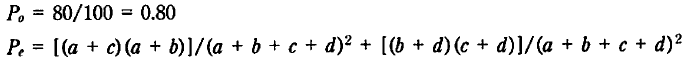
これは偶然に一致する事例数である。
この例の期待一致率は次のようになる。
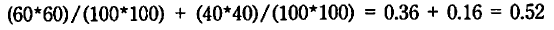
そのため、この例のカッパは次のように計算する。
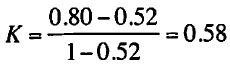
カッパは−1から+1の範囲を取る。
実測一致率が偶然一致率と同じ場合は0になり、すべての事例が一致した場合には1になる。
特定のカッパ値が高いか低いかを判断する絶対的な基準はないが、次のLandisとKochが発表した指針(1977年)を利用する研究者もいる。


この基準では、この例の2つの検査は中程度の一致を示している。
なお、この例の一致率は0.80であるが、カッパは0.58である。
カッパは偶然一致率を補正するので、常に一致率以下になる。
カッパに関する別の見解(より進んだ統計家向け)については、次の議論がある。
カッパに関する議論
コーエンのカッパは一般的に教えられ広く使われている統計量であるが、その妥当性は議論の余地がないわけではない。
通常、カッパは偶然による一致を超えた一致率を表すもの、または単に偶然を補正した一致率と定義される。
カッパには2つの用途がある。
2つの一連の評価が偶然による一致よりも一致率が高いかどうかを判断する検定統計量(二値のはい/いいえの判断)としての用途と、一致水準の尺度(0から1の数値で表す)としての用途である。
ほとんどの研究者はカッパの最初の用途に何も問題を感じないが、2つ目の用途には反対する研究者もいる。
問題は、2つの要素(評価者)間の偶然による一致率の計算は、評価が独立であることを前提としており、実際には通常この条件は満たされないことだ。
カッパは複数の個人が同じ事例を評価する際の一致度を定量化するために使われることが多いため、子供の教室での行動であろうと結核を患う人の胸部×線であろうと、偶然による一致率以上を期待するものだ。
このような場合、カッパは実際には偶然による実測一致率を過小評価するため、検査、評価者などの間の一致率を過大評価する。
関連リンク








