
カイ2乗検定に必須!イエーツ補正で精度向上【東京情報大学・嵜山陽二郎博士のAIデータサイエンス講座】

イエーツの連続性の補正は、イギリスの統計学者フランク・イエーツが開発した方法で、カイ2乗検定を2×2の表に適用する際に用いられます。カイ2乗分布が連続的である一方、データは離散的なため、この補正でそのズレを調整します。補正方法は簡単で、観測値と期待値の差の絶対値から0.5を引いてカイ2乗統計量を計算します。これにより第一種過誤を減少させますが、過剰修正による第二種過誤のリスクもあります。疎なデータには有用ですが、統計家の中には反対意見もあります。
![]() ▼▼▼▼▼▼▼▼
▼▼▼▼▼▼▼▼
チャンネル登録はこちら
統計学におけるイエーツの連続性の補正
イエーツの連続性の補正は、イギリスの統計学者イエーツ(Frank Yates)が独立性に対するカイ2乗検定を2×2の表に適用するときのために開発した手法である。
カイ2乗分布は連続的であるが、カイ2乗検定に使うデータが離散的である場合、イエーツの補正はこの食い違いを補正することを目的としている。
イエーツの補正を適用するのは簡単である。
カイ2乗統計量の式の(観測値一期待値)の絶対値から二乗する前に0.5を引くだけである。
これはカイ2乗統計値をわずかに減らす効果がある。

イエーツの連続性の補正を加えたカイ2乗の式を以下に示す。
イエーツの連続性の補正を加えたカイ2乗の式
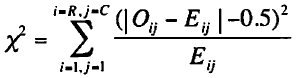
イエーツの補正は、カイ2乗値が小さくなるほど第一種過誤(間違って帰無仮説を棄却する)の確率が減るという考え方に基づいている。
しかし、イエーツの補正は普遍的に使用できるわけではない。
過剰修正により検出力を損ない、第二種過誤(間違って帰無仮説を棄却できない)の確率が高まると感じる研究者もいる。
イエーツの補正の利用を完全に拒否する統計家もいるが、疎データ(特に少なくとも表内の1つのセルの期待度数が5未満の場合)には有益であると考える統計家もいる。
疎なカテゴリデータに対するあまり異論のない補正方法は、以前に示した分布の前提(期待値が5未満のセルが20%未満で、期待値が1未満のセルがない)が満たさていないときにはカイ2乗検定の代わりにフィッシャーの正確確率検定を利用する方法である。
カイ2乗検定は2×2より大きい表で計算されることが多いが、セル数が増えると必要な計算が急激に増えるので、通常は解析には統計ソフトを使用する。
追加できる列と行の数には理論的限界はないが、2つの要因が実質的な限界を定める。
それは一貫した結果の解釈を行える可能性(30×30の表で試してみてほしい)と、前述したように疎なセルを避ける必要性である。
ときには、多数のカテゴリでデータを収集するが、疎なセルの問題を避けるために小数のカテゴリに集約することもある。
例えば、婚姻区分に関する情報を多くのカテゴリ(既婚、未婚、離婚、同棲、死別)を使って収集するが、特定の分析では小規模なカテゴリのデータが不十分なために統計学者がカテゴリを減らすこともある(例えば既婚と独身など)。
関連リンク








