
カイ2乗検定で解明!カテゴリ変数の独立性を検証【東京情報大学・嵜山陽二郎博士のAIデータサイエンス講座】

カイ2乗検定は、2つ以上のカテゴリ変数の関係を調べるための統計手法で、最も一般的なものはピアソンのカイ2乗検定です。独立性に対するカイ2乗検定は、変数が互いに独立であるかどうかを確認します。例えば、喫煙と肺癌の関係を調べる際、喫煙者と非喫煙者の肺癌発症率が異なるかを検証します。カイ2乗統計量は観測値と期待値の差を用いて計算され、自由度とカイ2乗分布に基づいて帰無仮説を棄却するか判断します。他にも、割合の等価性や適合度を検証するカイ2乗検定があり、それぞれ異なる仮説を検定するために使用されます。カイ2乗検定の要件には、独立した観測とカテゴリの排他性、期待値が1未満のセルがないことなどがあります。
![]() ▼▼▼▼▼▼▼▼
▼▼▼▼▼▼▼▼
チャンネル登録はこちら
統計学におけるカイ2乗検定
カイ2乗検定は、2つ以上のカテゴリ変数の関係を調べる最も一般的な手段の1つである。
カイ2乗検定を実施するには、カイ2乗統計量を計算し、その値とカイ2乗分布の値を比較して検定結果の確率を求める必要がある。
カイ2乗検定にはいくつかの種類がある。
特に明記しなければ、「カイ2乗検定」とはピアソンのカイ2乗検定を意味し、これが最も一般的な種類である。
カイ2乗検定には3つのバージョンがある。
独立性に対するカイ2乗検定
1つ目は独立性に対するカイ2乗検定と呼ばれる。
2変数を調べるために、独立性に対するカイ2乗検定では変数が互いに独立である(つまり、変数間に関連がない)という帰無仮説を検定する。
対立仮説は変数間に関連があり、独立ではなく従属であるというものになる。
例えば、成人の無作為標本から喫煙状態と肺癌の診断に関するデータを収集する。
各変数は二値である。
現在喫煙しているかしていないか、そして肺癌と診断されているか否かである。
このデータを以下表に示す度数分布表に並べる。
喫煙状態と肺癌診断
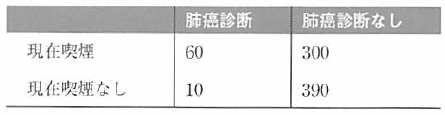
このデータを見るだけで、喫煙と肺癌に関係があるのはもっともらしく思える。
喫煙者の20%が肺癌と診断されているのに対し、非喫煙者ではたった約2.5%である。
しかし、見かけは当てにならないことがあるので、独立性に対するカイ2乗検定を実施する。
仮説は次のようになる。
H0:喫煙状態と肺癌診断は独立である。
H1:喫煙状態と肺癌診断は独立ではない。
特に大きな表では通常カイ2乗検定はコンピュータを使って実行するが、簡単な例では計算の手順を手動で順を追って行ってみる価値がある。
カイ2乗検定は、2×2の表の各セルの観測値と期待値の差を使う。
観測値は単に標本やデータ集合内で見つけた(観測した)値であるのに対し、期待値は2変数が独立であった場合に期待される値である。
あるセルの期待値を計算するには、以下式を使う。
セルの期待値の計算
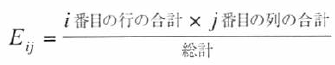
この式では、Eijはセルijの期待値であり、iとjはセルの行と列を示す。
この添字記法は統計の至るところで使われる。
また以下表は、添字記法を使って2×2の表の各部分を特定する方法を表す。
2×2の表の添字記法

以下表は、喫煙/肺癌の例に行と列の合計を追加している。
行と列の合計を加えた喫煙と肺癌のデータ
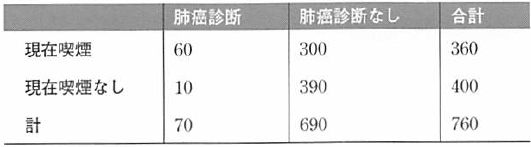
セル11の度数は60,セル12の値は300、行1の合計は360、列1の合計は70などとなる。
ドット記法を使うと、行1の合計は1.と表し、行2の合計は2.、列1の合計は.1、.2は列2の合計となる。
この記法の論理は、例えば行1の合計には列1と2の両方の値が属するので、列の位置をドットで置き換える。
同様に列合計には両方の行の値が属するので、行の位置をドットで置き換える。
この例では、1. = 360、2. = 400、.1 = 70、.2 = 690である。
列と行の合計の値は表の周辺にあるので周辺値と呼ばれる。
周辺値は、調査での一方の変数との関係を考慮しない他方の変数の度数を示すので、この表での肺癌診断の周辺度数は70、喫煙の周辺度数は360である。
表内の数値(この例では60、300、10、390)は両方の変数の特定の値を持つ事例の数を示すので、同時度数と呼ばれる。
例えば、この表で肺癌診断を受けた喫煙者の同時度数は60である。
2変数に関連がない場合、各セルの度数は周辺値の積を標本サイズで割ったものになると見込まれる。
言い換えると、同時度数は周辺値の分布にのみ影響を受けると見込まれる。
つまり、喫煙と肺癌が無関係であれば、この標本の喫煙者で肺癌を患っている人数は喫煙者数と肺癌者数だけで決まると見込まれる。
この論理によると、喫煙と肺癌の発症に関連がないことが真であれば、肺癌の確率は喫煙者と非喫煙者でほぽ同じになるだろう。
以下に示すように各セルの期待値を計算できる。
セルの期待度数の計算
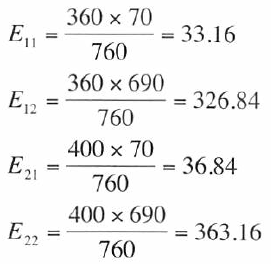
肺癌データの観測値と期待値を以下表に示す。
各セルの期待値は括弧で示している。
観測位と期待値の相違が偶然によるものなのか有意な結果を表すのかを判断する方法が必要である。
この判断はカイ2乗検定を使って下すことができる。
喫煙と肺癌のデータの観測値と期待値
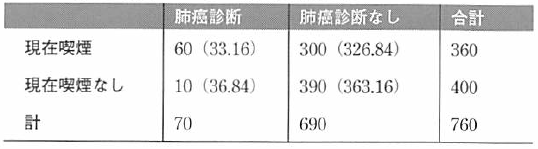
カイ2乗検定は以下式を使い、各セルの観測値と期待値の差の2乗に基づいている。
カイニ乗値を求める式
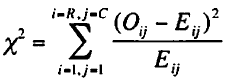
この式を使う手順は次のようになる。

この例のセル11では、この値は次のようになる。
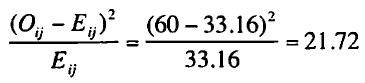
他のセルでも同様に計算を続けると、セル12では2.2、セル21では19.6、セル22では2.0となる。
合計は45.5であり、これはSPSS統計分析プログラムを使って求めた値(45.474)の丸め誤差内である。
カイ2乗統計量を解釈するには、自由度を知る必要がある。
カイ2乗分布はそれぞれ異なる自由度を持ち、そのため棄却値も異なる。
簡単なカイ2乗検定では、自由度は(r-l)(c-l)である。
つまり、(行数引く1)掛ける(列数引く1)である。
2×2の表では、自由度は(2-1)×(2-1)で1、3×5の表では(3−1)(5−1)で8となる。
カイ2乗値と自由度を手計算したら、カイ2乗表を調べてデータから計算したカイ2乗値が関連分布の棄却値を超えているかどうかを確認できる。
α=0.05の棄却値は3.841であるのに対し、ここでの値45.5ははるかに大きいので、α= 0.05の場合には変数が独立であるという帰無仮説を棄却する十分な証拠となる。
通常、コンピュータプログラムはp値と一緒にカイ2乗値と自由度を返し、p値がα水準よりも小さい場合には、帰無仮説を棄却できる。
この例では、アルファ値0.05を使っているとする。
SPSSによると、45.474という結果のp値は0.0001よりも小さく、これは0.05よりもはるかに小さいので、喫煙と肺癌に関係がないという帰無仮説を棄却すべきことを示している。

割合の等価性に対するカイ2乗検定
割合の等価性に対するカイ2乗検定は独立性に対するカイ2乗検定と全く同じ方法で計算するが、別の種類の仮説を検定する。
割合の等価性に対する検定は、複数の独立母集団から抽出したデータに使用し、帰無仮説はある変数の分布が全母集団で同じであるというものである。
例えば、さまざまな民族グループから無作為標本を抽出し、肺癌診断の割合が母集団ごとに同じか異なるかを検定できる。
その場合の帰無仮説は割合が同じというものになる。
計算は前述の例と同様に行う。
民族グループと肺癌状態で分類し、期待値を計算し、カイ2乗統計量と自由度の値を求めて適切な自由度のカイ2乗値の表と比較するか、または統計ソフトウェアパッケージで正確なp値を収得する。
適合度のカイ2乗検定
適合度のカイ2乗検定は、母集団のカテゴリ変数の分布が特定の割合パターンに従っているという仮説を検定するのに使うが、対立仮説はその変数の分布が別のパターンに従っているというものになる。
この検定は仮説割合に基づいた期待値を使って計算し、さまざまなカテゴリやグループは以下式に示すように添字i(1からgまで)で表す。
適合度のカイ2乗検定の式
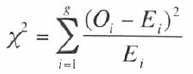
この式では、添字が1つだけである(例えば、EijではなくEi)。
これは、適合度のカイ2乗のデータは通常1行に並べられるので、1つの添字しか必要ないからである。
適合度のカイ2乗検定の自由度は(g−1)である。
特定の母集団の10%が低血圧であり、40%が正常血圧、30%が前高血圧、20%が高血圧であると考えているとする。
この仮説は、標本を抽出して観測割合と仮説割合(期待値)を比較すれば検定できる。
α= 0.05を使う。
以下表は、仮想データを使った例を示す。
血圧値の分布の期待値と観測値

このデータのカイ2乗計算値は自由度3で21.8であり、有意である。
α=0 .05での棄却値は7.815で、この値をはるかに超えている。
このデータでの計算値は棄却値を超えているので、この母集団の血圧値がこの仮説分布に従っているという帰無仮説を棄却すべきである.
ピアソン(Karl Pearson)のカイ2乗検定は、すべての観測値が独立であり(例えば、同じ人を2回測定しない)、カテゴリが互いに排反で網羅的である(1つ以上のセルに分類される事例がなく、起こり得るすべての事例をセルのいずれかに分類できる)データに適している。
また、期待値が1未満のセルはなく、期待値が5未満のセルは20%未満であると仮定する。
最後の2つの要件の理由は、カイ2乗が漸近検定であり、疎データ(1つ以上のセルの期待度数が低いデータ)には有効ではない可能性があるからだ。
関連リンク








